
ChatGPT に学習させない設定はなぜ必要?情報漏洩のリスクを整理
ChatGPT の無料版や Plus などの個人向けプランでは、初期設定のまま使うと、入力した会話の内容が AI モデルの改善(再学習)に使われる場合があります。これは OpenAI がサービスの精度を高めるための仕組みですが、業務で使う側にとっては注意が必要なポイントです。
たとえば顧客の氏名や連絡先、契約書の文面、社外秘の企画書などをそのまま貼り付けて要約や添削を依頼すると、その情報がモデルの学習データに取り込まれる可能性があります。学習に使われた内容が他のユーザーの回答にそのまま出てくるわけではありませんが、「外部のサービスに機密情報を渡し、かつ再利用される状態」になること自体がリスクと見なされます。
そのため、入力内容を学習に使わせない「オプトアウト」と呼ばれる設定が用意されています。オプトアウト(opt-out)とは、初期状態で有効になっている機能を、利用者の意思で無効にすることを指します。次の章から、具体的な設定手順を見ていきます。
関連記事:生成AIで気をつけるセキュリティとは?主要リスクと企業がとるべき対策を解説
ChatGPT に学習させない設定方法(オプトアウト)の手順
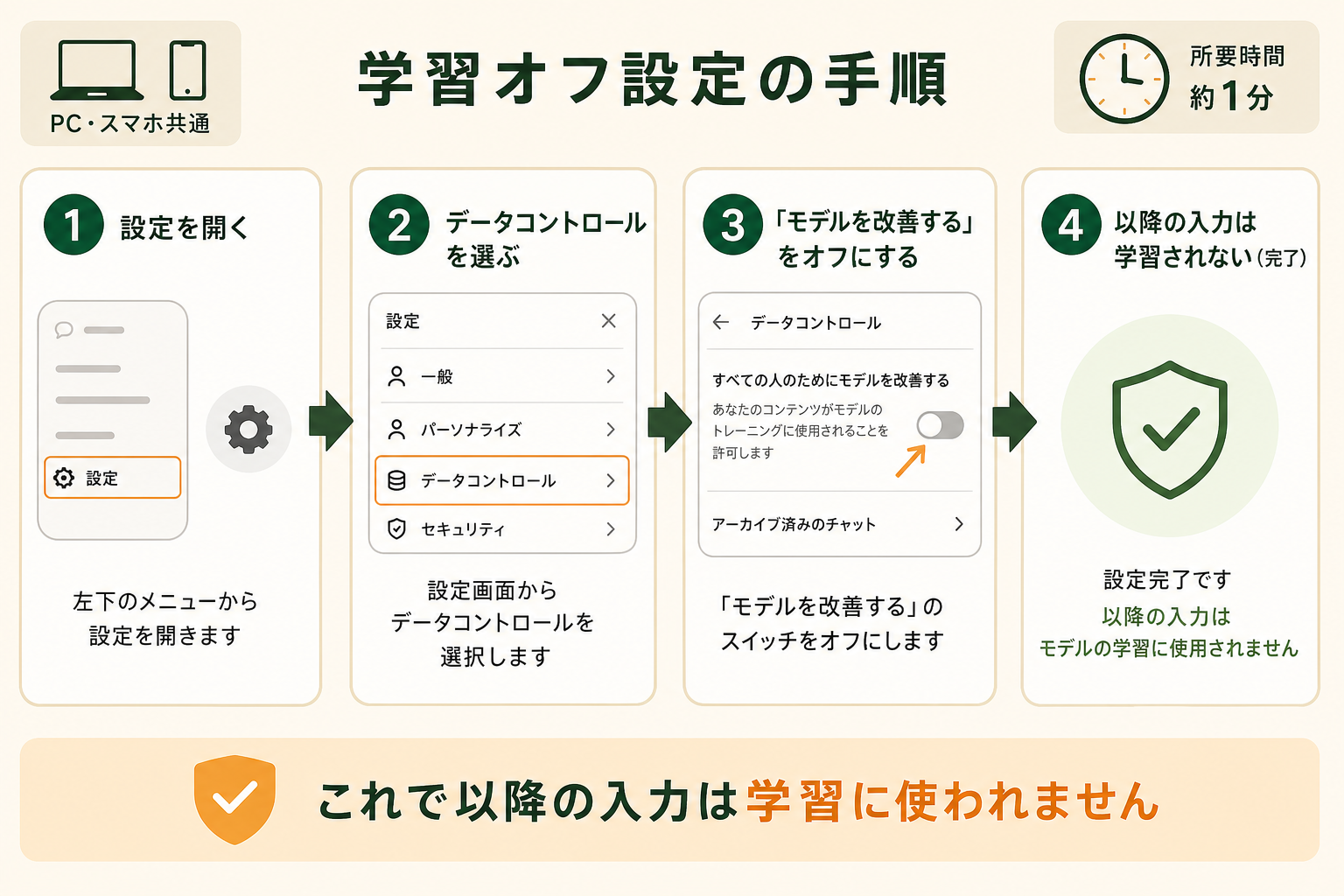
入力内容を学習させないための基本設定は、「データコントロール」から「モデルの改善に使う」項目をオフにするだけで完了します。所要時間は 1 分ほどです。PC とスマホで画面が少し異なるため、それぞれの手順を順番に解説します。
PC(ブラウザ版)で学習をオフにする手順
パソコンのブラウザから設定する場合は、次の手順で進めます。
- 画面右上のアカウントアイコンをクリックし、「設定(Settings)」を開く
- メニューから「データコントロール(Data controls)」を選ぶ
- 「すべての人のためにモデルを改善する」(Improve the model for everyone)のスイッチをオフにする
- 確認画面が出たら、オフにする旨を選んで完了する
このスイッチをオフにすると、それ以降に入力した会話は AI モデルの再学習には使われなくなります。設定はアカウント単位で保存されるため、同じアカウントでログインすれば別の端末にも反映されます。
スマホ(アプリ版)で学習をオフにする手順
スマートフォンの公式アプリ(iPhone・Android 共通)でも、同じ項目を操作します。
- 画面の左上または右下のメニューからアカウント名をタップし、「設定」を開く
- 「データコントロール」をタップする
- 「すべての人のためにモデルを改善する」をオフに切り替える
アプリ版は OS やバージョンによってメニューの位置が変わることがありますが、「設定」から「データコントロール」へ進む流れは共通です。項目名が英語で表示される場合は「Improve the model for everyone」を探してください。
一時チャットで会話単位で学習を止める
アカウント全体ではなく、特定の会話だけを学習や履歴から外したい場合は、「一時チャット(Temporary Chat)」が便利です。新規チャットの画面上部から一時チャットに切り替えると、その会話は履歴に保存されず、モデルの学習にも使われません。
機密情報を一度だけ扱いたいときや、普段は履歴を残しつつ特定の相談だけ秘匿したいときに向いています。通常のオプトアウト設定と組み合わせれば、状況に応じた使い分けができます。
「履歴オフ」と「学習オフ」は別物|設定の落とし穴とデメリット
学習させない設定でつまずきやすいのが、「チャット履歴をオフにすれば学習も止まる」という思い込みです。実際には履歴の保存と学習への利用は別の仕組みであり、混同すると対策が不十分になります。
履歴をオフにしても学習が止まるとは限らない
過去のバージョンでは「履歴とトレーニング」がひとつの設定にまとまっていましたが、現在は履歴の保存可否とモデル改善への利用可否が分かれています。そのため、画面上で「履歴」に関する項目だけを操作しても、モデル改善への利用がオンのままでは学習を止められないことがあります。
確実に学習を止めたい場合は、前章の「すべての人のためにモデルを改善する」のスイッチがオフになっているかを必ず確認してください。表示が更新されている場合もあるため、項目名そのものよりも「モデルの改善・トレーニングに関する設定がオフか」という観点で見るのが安全です。
設定をオフにするデメリット
学習をオフにすることには、いくつか引き換えになる点があります。主なデメリットは次の 3 点です。
- 過去のやり取りを後から見返せなくなる場合がある(履歴も併せてオフにしたとき)
- 自分の利用傾向を踏まえた回答の最適化(パーソナライズ)が効きにくくなる
- 端末をまたいだ会話の同期ができなくなることがある
いずれも業務に致命的な支障を与えるものではありませんが、過去のやり取りを資料として残したい場合は、履歴は保持しつつモデル改善の利用だけをオフにする、といった調整が向いています。利便性と安全性のバランスを見ながら設定するとよいでしょう。
設定前に入力した過去のデータはどうなる?削除を申請する方法
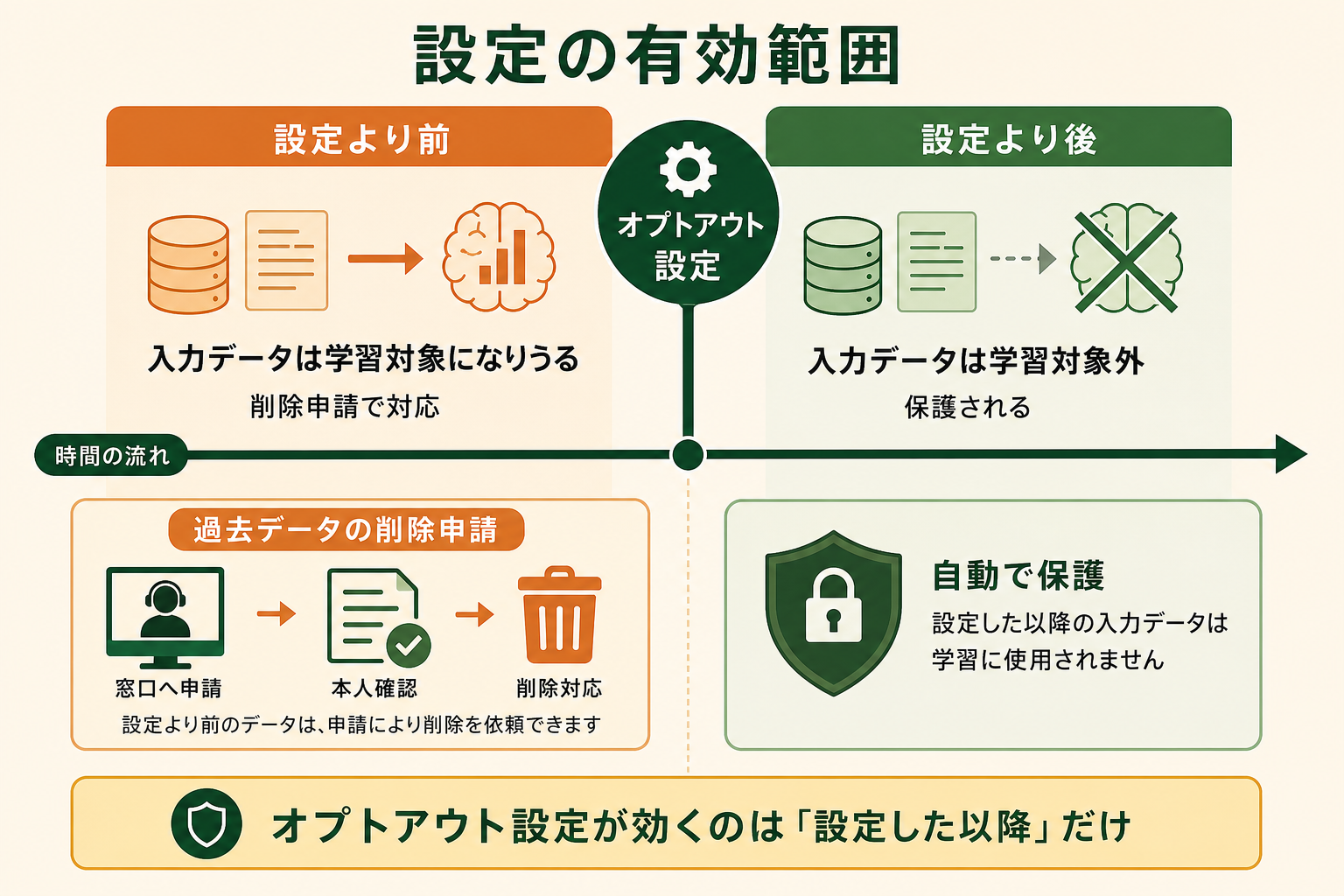
オプトアウト設定が効くのは、あくまで設定をオンにした「以降」の会話です。設定する前にすでに入力してしまった内容については、学習に使われる対象に含まれている可能性があります。この点を知らないまま「設定したから過去の分も大丈夫」と考えるのは危険です。
過去に入力したデータの取り扱いが気になる場合は、OpenAI のプライバシーリクエスト窓口(プライバシーポータル)から、自分のデータの削除や利用停止を申請できます。窓口では本人確認のうえで、保有データの開示や削除に対応する仕組みが用意されています(出典: openai.com)。
申請には一定の時間がかかることや、不正利用の監視など一部の目的で必要なデータは即時には削除されない場合があります。まずはオプトアウト設定で「これから先」の入力を守りつつ、過去分が心配な場合は削除申請を検討する、という二段構えで考えると整理しやすくなります。
法人向けに設定不要で安全に使う方法(Team・Enterprise・API)
ここまでは個人の設定による対策を解説してきましたが、組織でまとめて安全に使いたい場合は、最初から学習に使われないプランを選ぶ方法もあります。ChatGPT の法人向けプランや API では、入力したデータがデフォルトでモデルの学習に使われない仕組みになっています。
具体的には、複数人で使う「Team」、大規模組織向けの「Enterprise」、開発者がシステムに組み込む「API」などが該当します。これらは個々のメンバーがオプトアウト設定をしなくても、初期状態で学習対象から外れているため、設定漏れによる情報漏洩を防ぎやすくなります。
プラン別のデータの扱いを整理すると、次のようになります。
| プラン | 入力データの学習利用(初期状態) | 学習を止める方法 |
|---|---|---|
| 無料版・Plus・Pro(個人向け) | 使われる場合がある | データコントロールでオプトアウト設定 |
| Team・Enterprise・Edu(法人向け) | 使われない | 設定不要(初期状態で対象外) |
| API・Playground(開発者向け) | 使われない | 設定不要(初期状態で対象外) |
上表は 2026 年 6 月時点の公開情報に基づく整理です(出典: openai.com)。データポリシーは改定されることがあるため、導入前には最新の公式情報を確認してください。組織として継続的に使うなら、個人設定に依存せず、初めから学習対象外のプランを選ぶほうが管理の手間を抑えられます。
関連記事:ChatGPTのセキュリティ対策|社内利用を禁止せず安全に使うためのルールと設定
オプトアウト設定をしても「完全な秘密」にはならない理由
オプトアウト設定は「モデルの再学習に使わせない」ための仕組みであり、「入力した内容が一切どこにも残らない」ことを保証するものではありません。この違いを理解しておくと、過信による情報漏洩を避けられます。
OpenAI は不正利用の監視やサービス運用のため、学習に使わない場合でも、入力データを一定期間(最大で 30 日程度とされています)保持することがあります。また、不正の疑いがあるケースなどでは、担当者がデータを確認する可能性も示されています。
つまり、オプトアウト済みであっても「一切人の目に触れない」とは言い切れません。本当に外部に出してはいけない最高機密の情報は、そもそも外部サービスに入力しないという判断も必要です。設定はリスクを下げる有効な手段ですが、「設定したから何を入れても安全」という考え方は避けるのが無難です。
機密情報を入力する前に確認したいセキュリティチェックリスト
設定だけに頼らず、入力する側の運用ルールを決めておくと、より安全に使えます。ChatGPT に情報を入力する前に、次の項目を確認する習慣をつけておくとよいでしょう。
- モデル改善への利用(学習)をオフに設定しているか
- 特に秘匿したい会話は一時チャットを使っているか
- 顧客の個人情報や契約情報など、そもそも入力を避けるべき情報ではないか
- 組織で使う場合、学習対象外のプラン(Team・Enterprise・API)を利用しているか
- 過去に機密情報を入力していないか、必要なら削除申請を検討したか
このチェックリストは、設定の有無だけでなく「何を入力してよいか」の判断軸も含めています。個人の設定と、入力前のひと手間を組み合わせることで、情報漏洩のリスクを実務レベルで下げられます。
関連記事:生成AIの社内ガイドラインの作り方5ステップ|企業事例と項目一覧
ChatGPT を業務で使い始めるときに陥りがちな3つの落とし穴
学習させない設定を済ませると、いよいよ業務での本格活用を考え始める段階に入ります。ここで多くの担当者がつまずく共通のパターンがあります。AI を自社の仕事に取り入れるときに陥りがちな落とし穴を、3 つに整理します。
落とし穴1:いきなり全社で全てをやろうとする
最初から多くの部門・多くの業務に一気に広げようとすると、設定やルールの統一が追いつかず、かえって混乱を招きます。利用範囲が広いほど情報管理の抜け漏れも起きやすくなります。
落とし穴2:壮大なAI活用戦略から考えて手が止まる
「全社でどうAIを活用するか」といった大きな構想から入ると、検討に時間がかかり、なかなか着手できません。完璧な計画を待つうちに、現場の小さな困りごとが放置されてしまいます。
落とし穴3:既製のチャット型AIでは業務フローに組み込みにくい
汎用のチャット型AIは手軽な一方で、自社の業務フローやセキュリティ要件に合わせた作り込みが難しく、定型業務に深く組み込むには物足りないことがあります。
スモールスタートで1業務をAIに任せることがポイント
これらの落とし穴を避ける近道は、いきなり全体を変えようとせず、まず 1 つの業務に絞って小さく試すことです。効果と安全性を確認しながら少しずつ広げるほうが、結果的に早く定着します。1 業務単位で自動化・効率化の手応えを得てから、対象を広げていくのが現実的な進め方です。
自社業務でAIエージェント活用を進めたい方へ
ここまで紹介した「設定で安全性を確保しつつ、1 業務から小さく始める」という進め方を、自社で実践したいとお考えの方もいらっしゃるかもしれません。
GiftXでは、自社の業務に合わせて安全に使えるAIエージェントの構築を支援するサービス「GiftX AIエージェント構築支援」を提供しています。セキュリティ要件を踏まえた1業務単位のスモールスタートから、業務フローに組み込めるレベルのAIエージェント構築までを伴走します。
詳細はGiftX AIエージェント構築支援のサービスサイトでご覧いただけます。
ChatGPT に学習させない設定に関するよくある質問
最後に、設定にまつわるよくある疑問をまとめます。
Q. ChatGPT に情報を学習させない方法はありますか?
A. あります。設定の「データコントロール」から「すべての人のためにモデルを改善する」をオフにすると、それ以降の入力は学習に使われなくなります。
Q. 学習をオフにするとどうなりますか?
A. 入力内容がモデルの再学習に使われなくなります。履歴も同時にオフにした場合は、過去のやり取りを見返せなくなることがあります。
Q. 無料版でも学習をオフにできますか?
A. できます。オプトアウト設定は無料版・Plus・Pro のいずれでも同じ手順で利用できます。
Q. API や法人向けプランは学習されますか?
A. API や Team・Enterprise などの法人向けプランは、初期状態で入力データが学習に使われない仕組みです。個別のオプトアウト設定は不要です。
まとめ:まず設定すべき項目と組織で整えるルール
ChatGPT に入力内容を学習させないためには、まず「データコントロール」から「すべての人のためにモデルを改善する」をオフにする設定を、最初に済ませておくのが第一歩です。あわせて、特に秘匿したい会話には一時チャットを使い、過去に入力したデータが心配な場合は削除申請を検討します。
組織で使う場合は、個人の設定漏れに頼らず、学習対象外の法人向けプランや API を選ぶことで、より確実に情報漏洩を防げます。設定によるリスク低減と、「何を入力してよいか」の運用ルールづくりをセットで進めることが、安全な活用の近道です。まずは 1 つの業務から小さく始め、効果と安全性を確かめながら広げていきましょう。
AIの安全な業務活用をご検討の方へ
本記事で紹介したような設定上の対策に加えて、自社の業務に合わせて安全にAIを活用したい・具体的に相談したいとお考えの方は、ぜひGiftX AIエージェント構築支援までお問い合わせください。
GiftX AIエージェント構築支援では、貴社のセキュリティ要件や業務に合わせて、1業務単位のスモールスタートから本番運用まで、AIエージェント構築をワンストップで支援します。ユースケースの洗い出しから、PoC、本番運用、社内ナレッジ化まで伴走します。
AI活用にご関心のある方は、ぜひ一度ご相談ください。
▶ GiftX AIエージェント構築支援の詳細・お問い合わせはこちら



