生成AIのセキュリティとは?従来の対策と何が違うのか
生成AIのセキュリティとは、大規模言語モデル(LLM)や画像生成モデルなどの生成AIを開発・提供・利用する過程で生じる新たな脅威に対処し、情報の機密性・完全性・可用性を確保するための技術と運用の総称です。
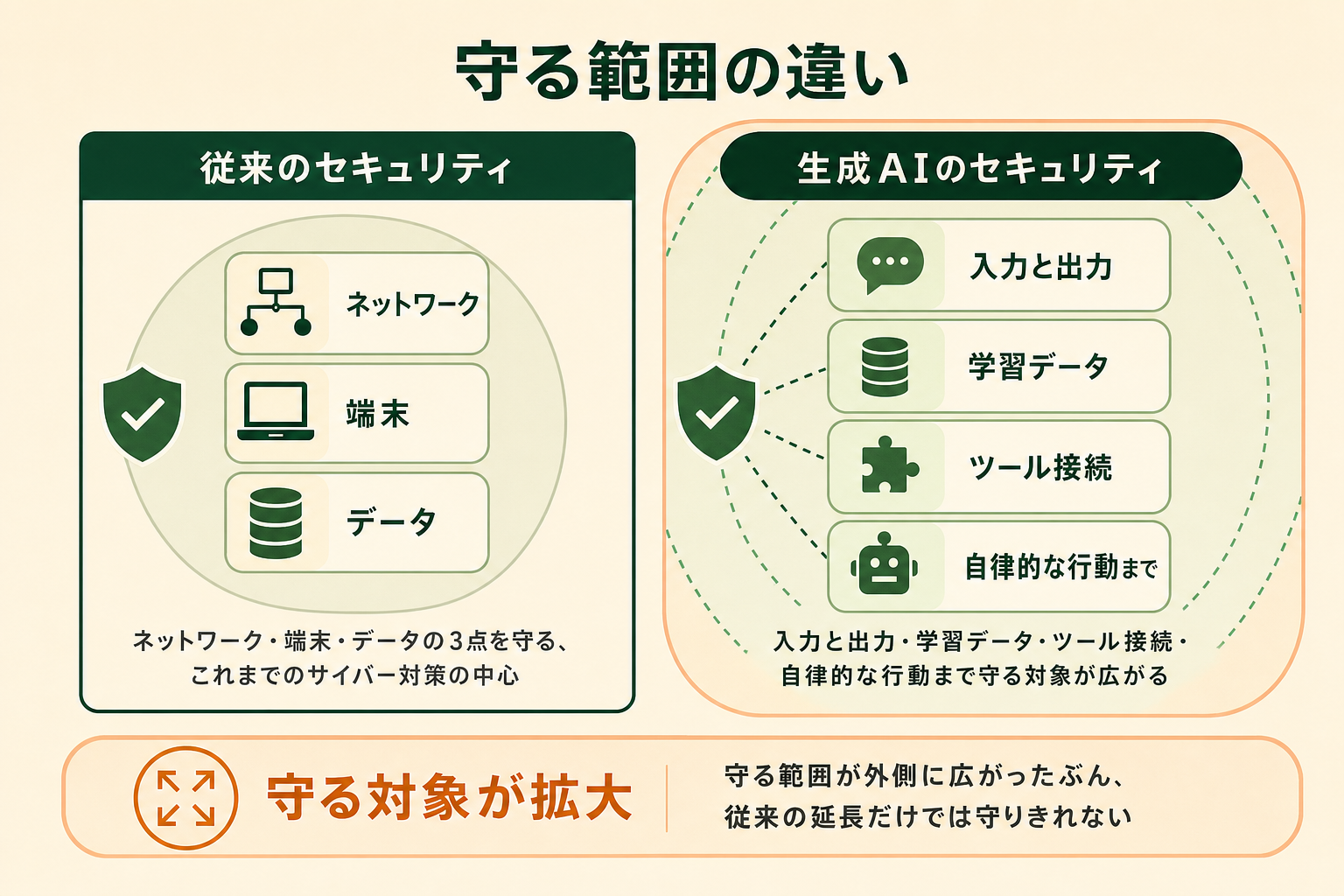
従来のサイバーセキュリティが「ネットワーク・端末・データ」を守ることを中心としてきたのに対し、生成AIのセキュリティでは「モデルへの入力と出力」「学習データ」「外部ツールとの接続」「AIの自律的な行動」までが保護の対象になります。これが、これまでの対策の延長だけでは守りきれない大きな理由です。
なぜいま対策が急務なのか
独立行政法人 情報処理推進機構(IPA)が公表した「情報セキュリティ10大脅威2026」では、「AIの利用をめぐるサイバーリスク」が組織向けの脅威の第3位にランクインしました(出典: ipa.go.jp)。生成AIのリスクは、もはや一部の先進企業だけが気にする特殊なテーマではなく、標準的なセキュリティ対策の中核に組み込むべき課題になっています。
背景には、現場主導で生成AIの利用が一気に広がった一方で、ルールや統制が追いついていないという実態があります。便利だからこそ無秩序に使われ、気づかないうちにリスクが蓄積していくのが、この領域の難しさです。
リスクを捉える3つの視点
生成AIのリスクを整理するときは、「利用する側」「提供・開発する側」「攻撃する側」の3つの視点で捉えると見通しがよくなります。自社が主に生成AIを「使う側」なのか「作る側」なのかによって、優先すべき対策の重心は変わります。多くの企業はまず「使う側」のリスク、つまり情報漏洩や誤情報の取り扱いから着手することになります。
生成AIならではの主要なセキュリティリスク6つ

生成AI固有のリスクは、国際的な脆弱性分類である「OWASP Top 10 for LLM Applications」や、国内のIPA・経済産業省のガイドラインで体系化されています。ここでは、ビジネスの現場でとくに注視すべき6つのリスクを整理します。
リスク1|プロンプトインジェクション
プロンプトインジェクションは、LLMが「命令」と「データ」を同じ入力として処理してしまう構造的な弱点を突き、攻撃者の意図する動作を引き起こす攻撃です。利用者が直接悪意ある指示を打ち込む「直接型」と、外部のWebページやメール、添付ファイルに指示を埋め込み、AIにそれを読み込ませる「間接型(インダイレクト)」に大別されます。OWASPの2025年版でも2年連続で最大のリスクに位置付けられており、現時点で確実な防御策はまだ確立されていないとされています。
リスク2|機密情報・個人データの漏洩
社員がプロンプトに機密情報を入力することで、外部の生成AIサービスに情報が流出するリスクです。2023年には韓国のサムスン電子で、技術者が半導体のソースコードや会議の議事録をChatGPTに入力し、機密情報が外部に渡ってしまった事例が報じられました(出典: ledge.ai)。同社はその後、社内での利用を一時的に禁止する対応をとっています。悪意のない利用が漏洩源になる点が、この問題の厄介なところです。
リスク3|ハルシネーション(誤情報の生成)
ハルシネーションは、生成AIが事実に基づかない情報を、もっともらしい体裁で出力してしまう現象です。米国では、弁護士が生成AIに作成させた訴訟書面に実在しない判例を記載し、裁判所から制裁金を科される事件も起きています。出力をそのまま社外向けの文書や顧客対応に使うと、企業が誤情報の責任を負う構図になりかねません。NISTのガイドラインでも独立したリスク領域として位置付けられています。
リスク4|ディープフェイク・なりすまし
画像・音声・動画の合成技術を使い、実在の人物になりすます攻撃です。2024年には香港の企業で、ビデオ会議に偽の経営幹部が複数人現れ、社員が指示どおり約2,560万ドル(およそ38億円)を送金してしまう詐欺事件が発生しました(出典: trendmicro.com)。攻撃者は公開されている動画やSNSから本人の映像・音声を収集していたとされ、公開情報だけで精巧な偽物が作れる時代になっています。
リスク5|AIエージェント特有のリスク(過剰な権限)
自律的にツールを呼び出して作業を進めるAIエージェントが、必要以上の権限を持つことで、意図しない動作や被害を引き起こすリスクです。とくにプロンプトインジェクションと組み合わさると、「外部から仕込まれた指示でAIが勝手にファイルを送信・削除する」といった形で被害が一気に拡大します。OWASPが2025年末に公開したエージェント向けの指針でも、「必要最小限の自律性のみを与える(Least Agency)」ことが中心原則とされています。
リスク6|サプライチェーン・モデル汚染
外部から取得したAIモデルや学習用データ、外部ツール接続の仕組みに、悪意あるコンテンツが含まれるリスクです。学習データに不正なサンプルを混ぜて特定の条件で誤動作させる「データ汚染(ポイズニング)」や、外部ツールの説明文に隠し命令を仕込む手口が代表例です。自社で開発・調整を行わない場合でも、利用するAIの「素性」を確認する視点が欠かせません。
実際に起きた生成AIのセキュリティインシデント事例
リスクを具体的にイメージするために、実際に報告された事例を見ておきましょう。いずれも「特別な企業だけの話」ではなく、生成AIを使うどの組織にも起こりうる構図を持っています。
ひとつ目は前述のサムスン電子の情報漏洩で、現場の利便性を優先した利用が機密流出につながった典型例です。ふたつ目は香港企業のディープフェイク送金詐欺で、約38億円という被害規模が、なりすまし攻撃の脅威を象徴しています。
さらに2025年には、企業向けの生成AIアシスタントである「Microsoft 365 Copilot」で、文書に隠した指示を読み込ませるだけで利用者の操作なしに機密データが外部に流出しうる脆弱性(CVE-2025-32711、通称EchoLeak)が報告されました。エンタープライズ向けの製品でも、間接型プロンプトインジェクションが現実の脅威であることを示した事例です。これらに共通するのは、「便利さの裏で、人もAIも気づかないうちに操作されてしまう」という点にあります。
生成AIのセキュリティを守る技術的対策
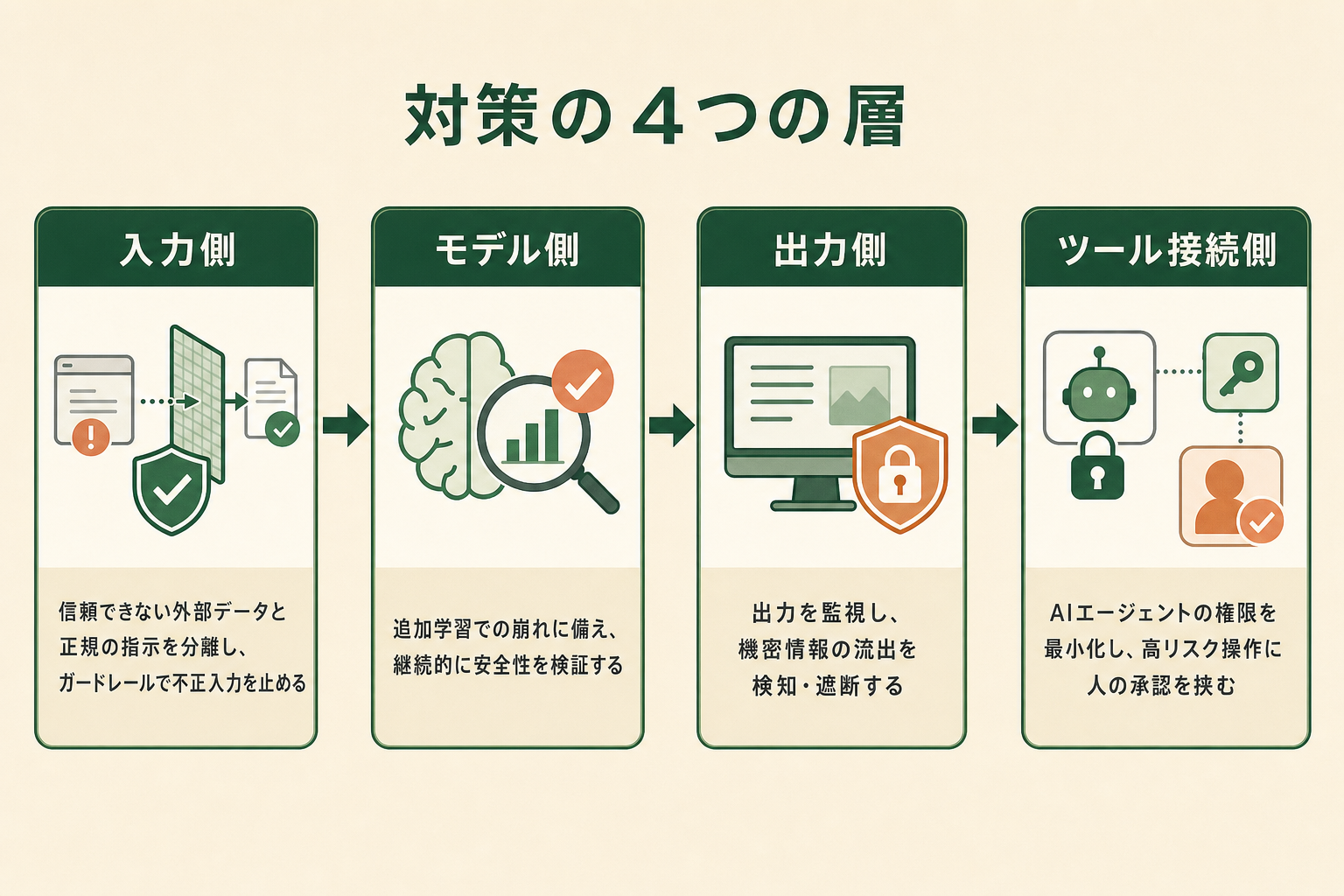
技術的な対策は、「入力側」「モデル側」「出力側」「ツール接続側」の各層に分けて考えると整理しやすくなります。ここでは、非エンジニアでも要点を押さえておきたい代表的な対策を紹介します。
入力の分離とガードレール
基本となるのは、信頼できない外部のコンテンツ(Webページ・アップロード文書など)と、開発者が与える正規の指示を明確に分離することです。外部から読み込んだデータを専用の枠で囲い、「この枠内の指示には従わない」とAIに明示する設計が一般的です。あわせて、不適切な入力や出力を検知してブロックする「ガードレール」と呼ばれる保護層を入出力に設けます。ただしガードレールは万能ではなく、追加学習(ファインチューニング)の過程で効果が崩れることも報告されているため、導入後も継続的な検証が前提になります。
AIエージェントの権限最小化
AIエージェントを使う場合は、呼び出せるツールをあらかじめ許可リスト方式で限定し、メール送信・ファイル削除・金銭のやり取りといった「書き込み」を伴う操作は必要なときだけ与えるのが基本です。リスクの高い操作には人間の承認を挟む「ヒューマン・イン・ザ・ループ」を組み込み、AIが暴走しても被害が広がらないようにします。「入力検証・出力検証・ツール権限制御・監査ログ」という4つの層で守る設計が提案されています。
RAG・社内データのアクセス制御
社内文書をAIに検索・参照させる「RAG(検索拡張生成)」を使う際は、参照元データベースのアクセス制御と暗号化が必須です。海外では、社内データを格納したデータベースがインターネット上に公開されたまま放置されていた事例も報告されており、設定ミスがそのまま情報漏洩に直結します。「誰がどのデータを参照できるか」を検索の前段で必ずチェックする仕組みを設けることが重要です。
組織・ガバナンスで進める生成AIの安全活用
技術的な対策だけでは不十分で、組織・運用ルールの整備が伴って初めて実効性が出ます。むしろ多くの漏洩事故は、技術の不備ではなく「ルールがないまま使われたこと」が原因です。
生成AI利用ポリシーの策定
最初のステップは、利用してよい生成AIサービスの範囲と入力してはいけない情報を明文化した「利用ポリシー」の策定です。IPAのガイドラインでも、これが組織的対策の出発点と位置付けられています(出典: ipa.go.jp)。ポリシーには、(1) 入力禁止情報の列挙(顧客の個人情報・営業秘密・未公開の財務情報・ソースコードなど)、(2) 利用を許可するサービスの一覧、(3) ログの保存と監査、(4) 問題発生時の連絡先と対応手順、(5) 違反時の取り扱い、を盛り込むのが標準的です。
従業員教育とシャドーAIの可視化
ルールを作っても、現場に浸透しなければ意味がありません。機密情報を入力しないこと、出力の誤りに注意すること、なりすまし詐欺の手口を知っておくことは、最低限の教育内容に含めるべきです。あわせて課題になるのが、会社が把握しないまま社員が個人契約で生成AIを使う「シャドーAI」です。利用状況を可視化する仕組みを導入し、安全に使える法人向けプラン(ChatGPT Enterpriseなど)へ誘導することで、無理なく統制を効かせられます。
インシデント対応体制の整備
情報漏洩や誤情報による対外的な事故など、生成AI特有のトラブルを想定した対応手順をあらかじめ準備しておきます。「何が起きたら誰に連絡し、どう止めるか」を事前に決めておくだけで、初動の速さが大きく変わります。新しいモデルや使い方を追加するたびにリスクを再評価する運用ループを回すことが、国際的な標準でも推奨されています。
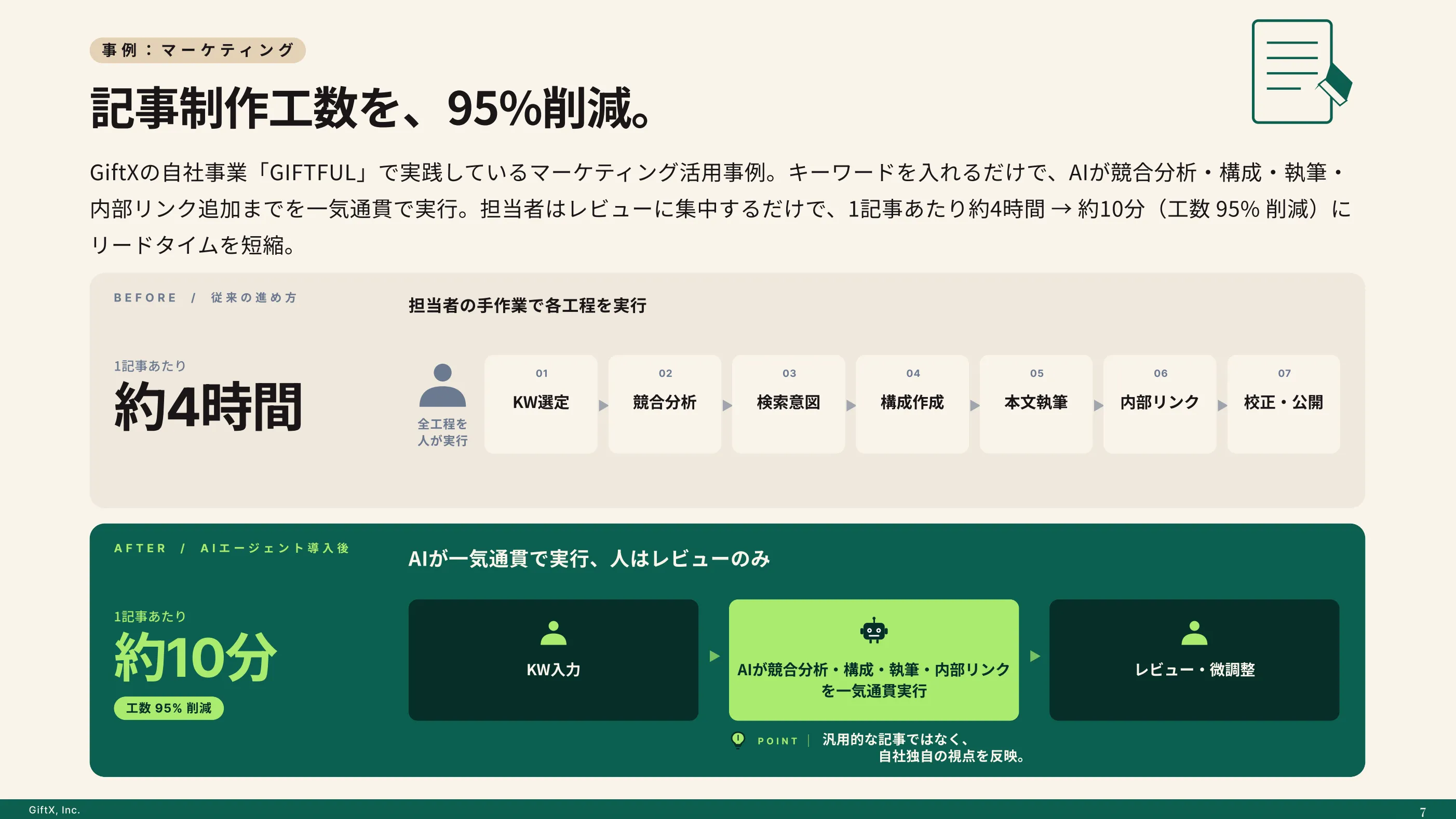
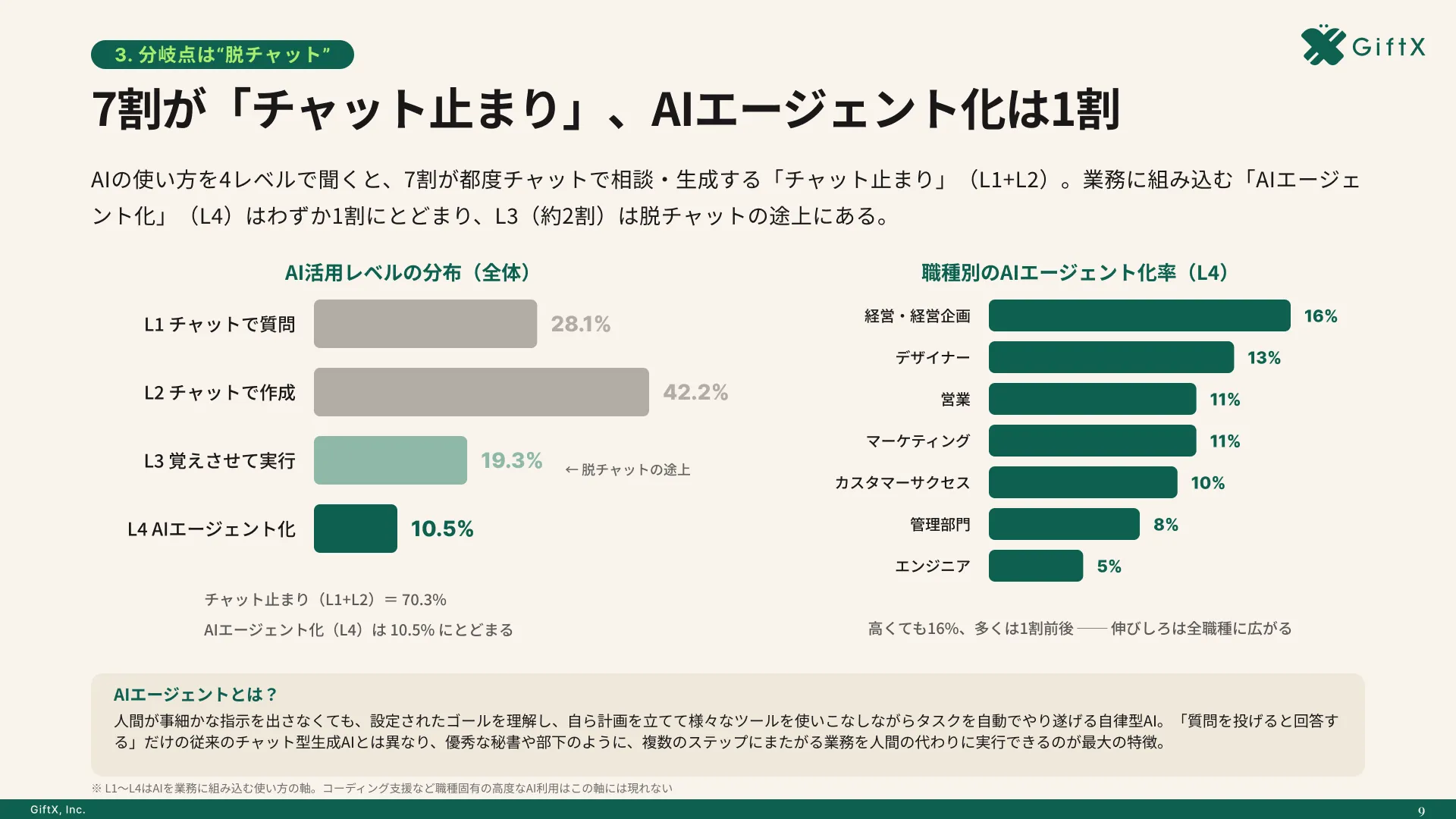
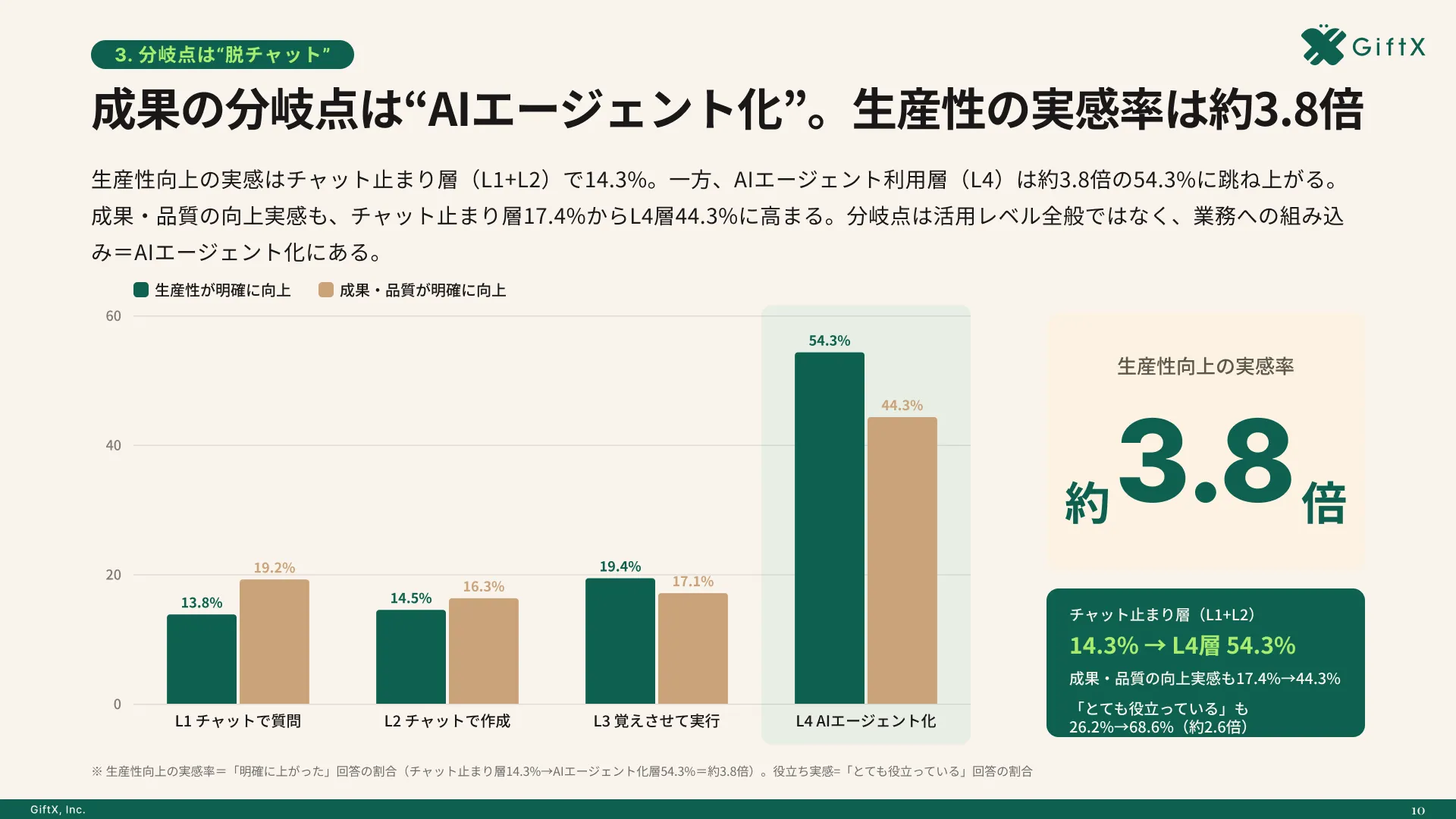
全国8,000人調査で、AI活用方法によって生産性向上に約3.8倍の差が生まれることが判明。
押さえておきたい国内外のガイドライン・法規制
生成AIに関するルールや規制は、ここ数年で急速に整備されてきました。すべてに精通する必要はありませんが、自社の方針づくりの拠り所として、主要なものの位置づけは押さえておきたいところです。
下表は、ビジネス担当者が知っておきたい代表的なフレームワーク・規制を、発行主体・性質・押さえどころの観点で整理したものです。国際標準を土台にしつつ、国内のガイドラインで具体的な運用に落とすのが基本的な進め方になります。
| 名称 | 発行主体 | 性質 | 押さえどころ |
|---|---|---|---|
| OWASP Top 10 for LLM | OWASP(国際団体) | 脆弱性分類のデファクト標準 | 開発・運用時の技術リスクの共通言語 |
| AI RMF 生成AIプロファイル | NIST(米国) | リスク管理の枠組み | 12のリスク領域と推奨アクション |
| ISO/IEC 42001 | ISO(国際規格) | AIマネジメントの認証規格 | 国際展開企業の事実上の標準 |
| AI事業者ガイドライン | 経済産業省・総務省 | 国内の統一指針 | 開発者・提供者・利用者の役割分担 |
| テキスト生成AI導入・運用ガイドライン | IPA(国内) | 実務的なリスク管理手法 | 利用ポリシー策定の具体的な手引き |
| EU AI Act | 欧州連合 | 世界初の包括的なAI規制 | リスクベースの4階層分類 |
このうち、EU AI Actは2025年8月から汎用目的AIの提供者への義務適用が始まり、学習データの公開や著作権遵守などが求められるようになりました(出典: ec.europa.eu)。国内では経済産業省・総務省の「AI事業者ガイドライン」が2026年3月に第1.2版へと改訂され、AIライフサイクル全体でのセキュリティ対策を求めています(出典: meti.go.jp)。海外メディアの報道によると、攻撃側と防御側の研究が激しく競り合う「いたちごっこ」の構図が続いており、規制と技術の両輪で備える重要性が増しています。日本でも同様の動きが広がりつつあるものの、まずは自社のリスクに合った範囲から着実に整えていくのが堅実な進め方です。
大企業と中小企業で異なる対策の優先順位
ここまで紹介した対策をすべて一度に実装するのは、どんな企業にとっても現実的ではありません。とくにリソースに差がある大企業と中小企業では、着手すべき順番が変わってきます。
潤沢な体制を持つ大企業であれば、AIマネジメントの認証取得や専門チームによる攻撃テスト(レッドチーミング)まで踏み込めます。一方、人員や予算が限られる中小企業がまず取り組むべきは、コストをかけずに効果が大きい「利用ポリシーの策定」と「従業員への入力禁止情報の周知」です。高度なツール導入よりも先に、「機密情報を生成AIに入力しない」という基本ルールを徹底するだけで、サムスン事例のような漏洩の大半は防げます。自社の体制に合わせて、守りの順番を見極めることが大切です。
生成AI・AIエージェントを安全に導入するときに陥りがちな3つの落とし穴
最後に、セキュリティを意識して生成AIの活用を進めようとする企業が、つまずきやすいポイントを3つ紹介します。安全性を高めようとするあまり、かえって何も進まなくなるケースは少なくありません。リスクを正しく恐れることと、過度に身構えて活用そのものを止めてしまうことは別物です。ここで紹介する3つの傾向は、まじめにセキュリティと向き合おうとする組織ほど陥りやすい点でもあります。
落とし穴1|いきなり全社・全業務に広げようとする
最初から全部門・全業務で安全に使えるようにしようとすると、検討すべきリスクが膨大になり、結局どこからも着手できなくなります。利用範囲が広いほど、統制すべき対象もリスクも増えていきます。たとえば部門ごとに扱う情報の機微度も、許容できるリスクの大きさも異なるため、すべてを同じルールで一度に縛ろうとすると、現場の実態に合わない過剰な制限になりがちです。結果として「使ってはいけない」とだけ決まり、肝心の活用が進まないまま時間だけが過ぎていきます。
落とし穴2|壮大なAIガバナンス構想から考えて手が止まる
「全社のAIガバナンス体制を完璧に設計してから」と考え始めると、検討だけで時間が過ぎ、現場の利用実態だけが先行してしまいます。立派な構想よりも、まず1つの業務で安全に回す経験を積むほうが、結果的に実効性のあるルールにつながります。実際にどんな情報がどう入力され、どこにリスクが生じるかは、使ってみて初めて具体的に見えてくるものです。机上で完璧なルールを作るより、小さく試してわかった課題をルールに反映していく順番のほうが、現場に根付く統制になります。
落とし穴3|既製のチャット型AIだけで何とかしようとする
汎用のチャット型AIは手軽ですが、自社のセキュリティ要件や業務フローに合わせた細かい作り込みが難しく、入力制御や権限管理を業務に組み込めるレベルまで届かないことがあります。「機密情報は入力しない」と人に注意を促すだけでは、うっかりミスを完全には防げません。守りたい範囲が明確な業務ほど、その業務に合わせて設計したAIエージェントのほうが、入力できる情報の範囲や呼び出せる機能をあらかじめ制限でき、結果的に安全に運用しやすくなります。
結論|スモールスタートで1業務から安全に任せる
これらの落とし穴を避ける鍵は、スモールスタートにあります。まず1つの業務に絞って生成AIやAIエージェントに任せ、その狭い範囲でセキュリティを担保しながら、運用しながらルールを育て、段階的に広げていくのが現実的な進め方です。守る対象が1業務に限定されていれば、入力される情報も呼び出される機能も把握しやすく、リスクを具体的に検証できます。そこで得た知見を土台に対象を広げていけば、無理なく全社の安全な活用へとつなげられます。GiftXでも、こうしたスモールスタート前提の安全なAIエージェント構築を1業務単位から伴走支援しています。詳しくはAIエージェント構築支援サービスをご覧ください。
生成AIのセキュリティに関するよくある質問
最後に、生成AIのセキュリティについて検索者からよく寄せられる疑問に、端的に回答します。
ChatGPTなどの生成AIを業務で使っても安全ですか?
利用ポリシーを定め、機密情報を入力しないなどの基本ルールを守れば、業務での利用は十分に可能です。法人向けプランでは入力データを学習に使わない設定が選べるものも多く、こうしたサービスを選ぶことでリスクを大きく下げられます。「使わない」より「安全に使う」前提で設計するほうが、無理なく業務に根付かせられます。
生成AIで情報漏洩が起きる主な原因は何ですか?
最も多いのは、社員がプロンプトに機密情報を入力してしまう人的な要因です。会社が把握しないまま個人利用される「シャドーAI」も大きな原因になります。技術的な攻撃よりも、まず日常の利用ルールの不備に目を向けることが重要です。
プロンプトインジェクションとは何ですか?
AIに与える指示(プロンプト)に悪意ある命令を紛れ込ませ、本来の動作を乗っ取る攻撃です。外部のWebページや文書に指示を仕込む間接型もあり、利用者が気づかないうちに実行される点が脅威となっています。
中小企業はまず何から対策すればよいですか?
コストをかけずに効果が大きい「利用ポリシーの策定」と「従業員教育」から始めるのがおすすめです。高度なツールの導入よりも先に、入力禁止情報を明確にして全社で共有するだけで、漏洩リスクの多くを抑えられます。
まとめ
生成AIのセキュリティは、従来の「ネットワークや端末を守る」発想だけでは対応しきれず、入力・出力・学習データ・ツール接続・自律的な行動まで含めて守る必要があります。プロンプトインジェクションや情報漏洩、ディープフェイクといった固有のリスクを正しく把握し、入力の分離や権限最小化などの技術的対策と、利用ポリシーや教育といった組織的対策を両輪で進めることが基本です。とはいえ、すべてを一度に完璧にしようとすると手が止まってしまいます。まずは1つの業務にしぼり、その範囲でセキュリティを担保しながら生成AIを安全に使う経験を積み、段階的に広げていくスモールスタートが、結果的にもっとも確実な進め方になります。
生成AIの安全な活用を、自社の業務で進めたい方へ
本記事で紹介した生成AI・AIエージェントの安全な活用について、自社の業務でも具体的に進めたい・相談したいとお考えの方は、ぜひGiftX AIエージェント構築支援までお問い合わせください。
GiftX AIエージェント構築支援では、貴社の業務に合わせて1業務単位のスモールスタートから本番運用まで、セキュリティを踏まえたAIエージェント構築をワンストップで支援します。ユースケースの洗い出しから、PoC、本番運用、社内ナレッジ化まで伴走します。
AI活用にご関心のある方は、ぜひ一度ご相談ください。
▶ GiftX AIエージェント構築支援の詳細・お問い合わせはこちら
関連記事
・AIエージェントの法人導入ガイド|PoCから本番運用までの5ステップと3つの落とし穴
・企業の生成AI活用事例15選|業務別・業界別の成功例と主要ツール・導入ステップ