Codexはなぜデータを学習する?情報漏洩・セキュリティのリスク
最初に、「学習させない設定」がなぜ必要なのかを押さえておきましょう。仕組みとリスクを理解しておくと、後半の設定手順の意味が腹落ちしやすくなります。
関連記事:Codexとは?OpenAIコーディングAIの仕組みやChatGPTとの違い、導入の落とし穴を解説
そもそもCodexは入力したデータを学習に使うのか
Codexは、ChatGPTを運営するOpenAIが提供するエージェント型のコーディングツールで、自然言語で指示すると既存のプロジェクトに合わせてコードを書き、ファイルの読み書きやコマンド実行まで行います。利用形態はターミナルで動くCLI、各種IDE拡張、ブラウザで使うクラウド版など多岐にわたります。
ここで重要なのは、Codexが「ChatGPTのサブスクリプションの一機能」として提供されている点です。つまり、入力したデータがモデルの学習に使われるかどうかは、Codex単体の設定ではなく、土台となるアカウント・プランのデータ取り扱いポリシーに従います。一般に、個人向けの対話サービスでは入力内容がモデル改善(学習)に利用される場合があり、これをオフにする「オプトアウト」の設定が用意されています。一方で、後述するAPIや企業向けプランでは、デフォルトで学習対象外として扱われます。
「学習に使われるかもしれない」と感じる不安の正体は、この「プランによって扱いが違う」という分かりにくさにあります。だからこそ、自分が使っている形態でどう設定すればよいかを正しく把握することが第一歩になります。
学習されることで生じる情報漏洩・セキュリティのリスク
入力データが学習に使われると、どのようなリスクがあるのでしょうか。最も警戒すべきは、機密情報の意図しない流出です。たとえば、未公開のソースコード、APIキーや認証情報、顧客データを含むコードを入力した場合、それがモデルの改善に取り込まれると、将来的に第三者への応答に痕跡が反映される懸念がゼロとは言い切れません。
また、生成AIには実在しないコンポーネントを参照する「ハルシネーション」や、学習元に古い実装やセキュリティ上問題のあるコードが含まれていればそれを再生産しうるという課題も指摘されています。出力をそのまま本番システムに使うのではなく、レビューを前提にする姿勢が欠かせません。
こうしたリスクは、入力データを学習に使わせない設定と、機密情報を不用意に入力しない運用ルールの両輪で抑えるのが基本です。次章から、具体的な設定手順を見ていきます。
【設定手順】Codexにコードやデータを学習させない方法
ここからが本題です。利用形態ごとに、データを学習に使わせないための設定手順を整理します。自分の使い方に当てはまる箇所から確認してください。
個人向けChatGPT・Codexでデータコントロールをオフにする手順
個人アカウント(Free・Plus・Pro)でCodexやChatGPTを使う場合、入力内容がモデル改善に使われる可能性があるため、明示的にオフにします。手順は次の通りです。
STEP 1:ChatGPTにログインし、画面右上または左下のアカウントメニューから「設定(Settings)」を開きます。
STEP 2:「データコントロール(Data Controls)」の項目を選びます。
STEP 3:「すべての人のためにモデルを改善する(Improve the model for everyone)」に相当するトグルをオフにします。これにより、入力した会話やコードがモデルの学習に使われなくなります。
STEP 4:設定が反映されているかを確認します。オフにした後の入力分から学習対象外になります。
この設定をオンからオフに切り替えても、応答の精度や機能が制限されることはありません。学習への提供と、ツールとしての利用品質は別物だと理解しておくと安心です。
Codex CLIで学習対象から除外する設定
ターミナルで動くCodex CLIも、紐づくOpenAIアカウントのデータコントロール設定に従います。そのため、上記の個人向け設定をオフにしておけば、CLI経由の入力も学習対象から外れます。
加えてCLIには、エージェントが実行できる操作を制限するセキュリティ制御が用意されています。書き込み先やネットワーク到達可否を制御する「サンドボックス」と、危険な操作の前に承認を求める「承認ポリシー」の2層です。学習の可否とは別に、こうした制御を活用することで、機密リポジトリでの不用意な操作や外部送信を抑えられます。
過去に入力したデータの履歴削除・リセット方法
「これまで入力した分はどうなるのか」という疑問もよくあります。多くの場合、設定画面のデータコントロール内から会話履歴のエクスポートや削除、アカウントデータの消去を依頼できます。学習をオフにするのは「これから」の入力に対する設定であるため、過去分が気になる場合は履歴の削除も合わせて行うとよいでしょう。
ただし、削除の反映には一定の時間がかかる場合や、不正利用監視などの目的で一定期間保持される場合があります。完全な即時削除を前提にせず、機密度の高い情報はそもそも入力しない運用を基本に据えるのが安全です。
プラン・利用形態別に異なるデータ学習ポリシー
Codexの「学習させない」を正しく理解するうえで、プラン・利用形態によってデフォルトの扱いが違うことを押さえておく必要があります。
無料版・有料版(Plus・Pro)でのデータ学習の扱い
個人向けの無料版および有料版(Plus・Pro)では、入力内容がモデル改善に使われる可能性があり、前章の手順で明示的にオフにする必要があります。「有料だから自動的に学習されない」わけではない点に注意してください。料金プランの違いは利用枠やモデルの選択肢に関わるものであり、学習の可否は別途データコントロールで管理する、と整理すると分かりやすいです。
API利用はデフォルトで学習対象外
OpenAIのAPI経由でCodex相当の機能を使う場合、入力・出力データはデフォルトでモデルの学習に使われない方針が示されています(出典: openai.com、2026年6月時点)。自社プロダクトやCI/CDパイプラインにプログラムから組み込むケースでは、API利用が学習リスクの面では扱いやすい選択肢になります。ただし、API利用でもデータが一定期間保持される場合があるため、提供元の最新のデータ利用ポリシーを必ず確認してください。
企業・エンタープライズプランはデフォルトで学習除外
Business・Enterprise・Eduといった企業向けプランでは、ワークスペースのデータがデフォルトで学習に使われない設計になっています。加えて、SAML SSOや多要素認証、監査ログといった統制機能が用意され、管理者がワークスペース全体のセキュリティ設定を一括管理できます。OpenAIはエンタープライズ向け提供についてSOC 2監査を完了しており、隔離された管理コンテナでの実行やコンプライアンスログの提供など、組織利用を前提とした設計が進んでいます。複数人で安全に使いたい場合は、個人プランを各自で設定するより、企業プランで統制をかけるほうが運用は確実です。
Claude・Gemini・GitHub Copilotの学習停止設定と比較
Codexだけでなく、他の主要AIでも「学習させない」設定の考え方は共通しています。横並びで比較しておくと、自社で複数ツールを使う際の判断がしやすくなります。下表は、個人利用時のデフォルトの学習可否、オプトアウトの可否、API・企業利用時の扱いの3観点で主要4ツールを整理したものです。いずれも「個人利用は明示設定、API・企業は原則学習対象外」という共通構造を持つ点に注目してください。
| 観点 | Codex(OpenAI) | Claude(Anthropic) | Gemini(Google) | GitHub Copilot |
|---|---|---|---|---|
| 個人利用時のデフォルト | 学習に使われる場合あり | 原則学習に使わない方針 | 学習に使われる場合あり | コードスニペットの扱いに設定あり |
| オプトアウト設定 | データコントロールでオフ | 設定・申請で管理 | アクティビティ設定でオフ | 設定でコード送信をオフ |
| API・企業利用時 | デフォルト学習対象外 | デフォルト学習対象外 | 企業向けは学習対象外 | 企業向けは学習対象外 |
実務上は、いずれのツールも「個人アカウントは自分でオプトアウト設定を確認する」「業務利用は企業プランやAPIに寄せて統制をかける」という二段構えが基本になります。たとえば、個人で試用する段階では各ツールの学習設定を必ずオフにし、本格利用に移る際は企業プランへ切り替える、といった運用が現実的です。各ツールの仕様は更新が早いため、導入前に提供元の最新ポリシーを確認することをおすすめします。
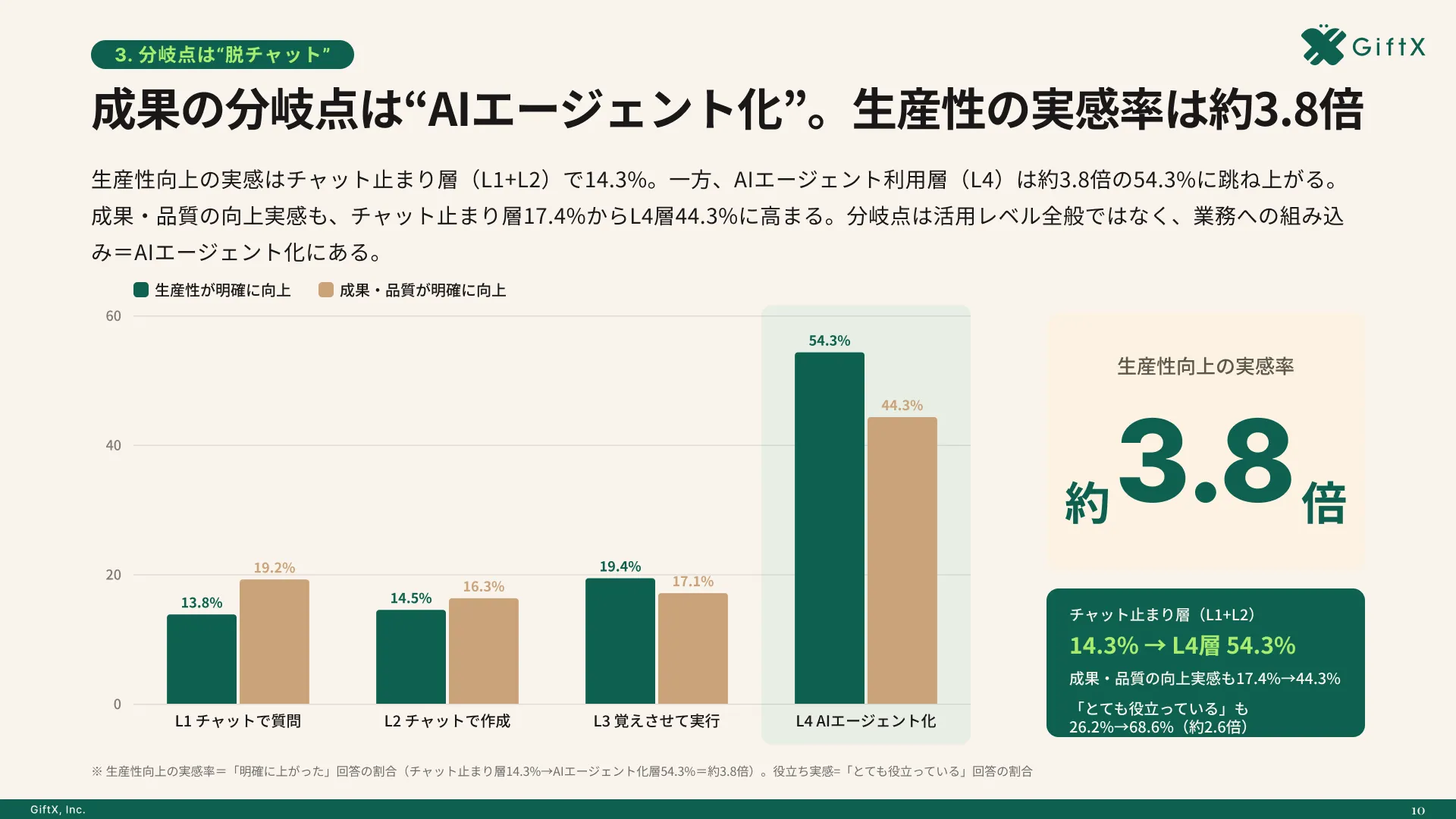
全国8,000人調査で、AI活用方法によって生産性向上に約3.8倍の差が生まれることが判明。
機密業界で押さえたい法規制とデータ学習の関係
ここまでの設定に加えて、業界によっては法規制の観点からデータの取り扱いを厳格に管理する必要があります。多くの記事が設定手順までで止まる中、ここは見落とされがちな差別化ポイントです。
個人情報や顧客データを扱う場合、日本の個人情報保護法では、本人の同意なく個人データを第三者に提供したり、目的外で利用したりすることが制限されます。AIへの入力がこれに該当しないかは、入力するデータの性質によって慎重な判断が必要です。海外の顧客データを扱う場合は、EUのGDPRなど、より厳格な規制への対応も求められます。
金融や医療のように機密性の高い情報を扱う領域では、そもそも生成AIに実データを入力しないことを原則とし、入力が避けられない場合は氏名・住所・識別番号などをマスキング(伏せ字化)・匿名化してから渡す運用が求められます。社内の利用ガイドラインに「入力してよい情報・いけない情報」を明文化し、担当者への周知を徹底することが、設定と並んで重要な守りになります。設定でリスクを下げ、ルールで運用を縛る。この組み合わせが、規制の厳しい領域で安心して使うための前提条件です。
関連記事:生成AIで気をつけるセキュリティとは?主要リスクと企業がとるべき対策を解説
すぐ使える「AIに学習させない」設定チェックリスト
最後に、ここまでの内容を実行に移すためのチェックリストをまとめます。導入前・運用中に上から順に確認してください。
- 利用しているプラン(個人・API・企業)でのデータ学習のデフォルトを把握したか
- 個人アカウントの場合、データコントロールでモデル改善への提供をオフにしたか
- 過去に入力した履歴の削除・エクスポートが必要かを判断し、対応したか
- 機密情報(認証情報・顧客データ・未公開コード)を入力しないルールを決めたか
- 入力が避けられない情報はマスキング・匿名化してから渡す運用にしたか
- 業務利用は企業プランやAPIに寄せ、管理者が統制をかける体制にしたか
- 該当する法規制(個人情報保護法・GDPR等)への対応を確認したか
- 社内の利用ガイドラインを文書化し、関係者に周知したか
これらは一度に完璧を目指す必要はありません。まずは「個人アカウントの学習オフ」と「機密情報は入力しない」の2つから着手すれば、当面のリスクは大きく下げられます。
生成AI・Codexを業務に取り入れるときに陥りがちな3つの落とし穴
データ学習の設定を押さえたら、いよいよ業務への活用です。ここでGiftXの視点から、AIを業務に取り入れる際に多くの組織がつまずく3つの落とし穴を共有します。
落とし穴1:いきなり全てをやろうとする
最初から複数の業務をまとめてAI化しようとすると、設定もルール整備も追いつかず、かえって混乱を招きます。対象を1つに絞らないまま広げると、どこにリスクがあるかも見えにくくなります。
落とし穴2:壮大なAI戦略から考えて手が止まる
「全社的にどう使うか」という大きな構想から入ると、検討が長引いて実行に移れません。安全性の議論も机上で止まりがちで、現場での学びが蓄積されません。
落とし穴3:既製品のチャット型AIでは業務フローに組み込めない
汎用のチャット型AIは手軽ですが、自社の業務手順やデータ管理ルールに合わせたカスタマイズが難しく、本当に任せたい工程に組み込めるレベルの質には届きにくいのが実情です。
スモールスタートで1業務をAIエージェントに任せる
これらを避ける鍵は、スモールスタートです。まず1つの業務に絞り、学習させない設定や情報の取り扱いルールを固めたうえでAIエージェントに任せる。小さく始めて成果と安全性を確かめてから次に広げる進め方が、結局は遠回りに見えて最短ルートになります。
自社業務でAIエージェント活用を進めたい方へ
ここまで紹介した「安全な設定を固めたうえで、1業務からスモールスタートする」アプローチを、自社で実践したいとお考えの方もいらっしゃるかもしれません。
GiftXでは、業務に特化したAIエージェントの構築支援サービス「GiftX AIエージェント構築支援」を提供しています。データの取り扱いやセキュリティ要件を踏まえながら、1業務単位のスモールスタートから、業務フローに組み込めるレベルのAIエージェント構築までを伴走します。
詳細はGiftX AIエージェント構築支援のサービスサイトでご覧いただけます。
よくある質問(FAQ)
最後に、データ学習に関してよく寄せられる質問に回答します。
ChatGPTやCodexに学習させない設定はどこにありますか
個人アカウントの場合、設定(Settings)内の「データコントロール(Data Controls)」から、モデル改善への提供をオフにできます。Codexはこのアカウント設定に従うため、ここをオフにすればCLIやクラウド版の入力も学習対象から外れます。
履歴をオフにしても学習されてしまうことはありますか
データコントロールで学習への提供をオフにした以降の入力は、原則として学習に使われません。ただし設定はオフにした時点以降に適用されるため、過去分が気になる場合は履歴の削除も合わせて行うのが確実です。
学習をオフにすると機能や精度は落ちますか
学習への提供をオフにしても、応答の精度やツールとしての機能が制限されることはありません。学習への協力と、利用時の品質は切り離して考えて問題ありません。
企業で安全に使うにはどうすればよいですか
企業利用では、データがデフォルトで学習対象外となるBusiness・Enterpriseプランの利用が基本です。あわせて、入力してよい情報の線引きを社内ガイドラインで明文化し、管理者が統制をかける体制を整えることをおすすめします。
まとめ
Codexに学習させないための第一歩は、自分の利用プランでのデフォルトを把握し、個人アカウントならデータコントロールでモデル改善への提供をオフにすることです。API・企業プランは原則として学習対象外ですが、それでも機密情報は入力しない運用と、マスキングや社内ガイドラインによるルール整備を組み合わせることで、安全性はさらに高まります。設定でリスクを下げ、ルールで運用を縛る。この両輪を押さえたうえで、まずは1業務からスモールスタートでAIエージェントを取り入れていくのが、安全に成果を出す近道です。
AI活用の伴走支援をご検討の方へ
本記事で紹介したように、AIを安全に業務へ取り入れるには、設定・運用ルール・スモールスタートの設計をセットで考えることが欠かせません。自社の業務に合わせて具体的に進めたい、相談したいとお考えの方は、ぜひGiftX AIエージェント構築支援までお問い合わせください。
GiftX AIエージェント構築支援では、貴社の業務に合わせて1業務単位のスモールスタートから本番運用まで、AIエージェント構築をワンストップで支援します。データの取り扱い設計から、ユースケースの洗い出し、PoC、本番運用、社内ナレッジ化まで伴走します。
AI活用にご関心のある方は、ぜひ一度ご相談ください。
▶ GiftX AIエージェント構築支援の詳細・お問い合わせはこちら