ハルシネーションとは?生成AIが事実と異なる情報を生成する現象
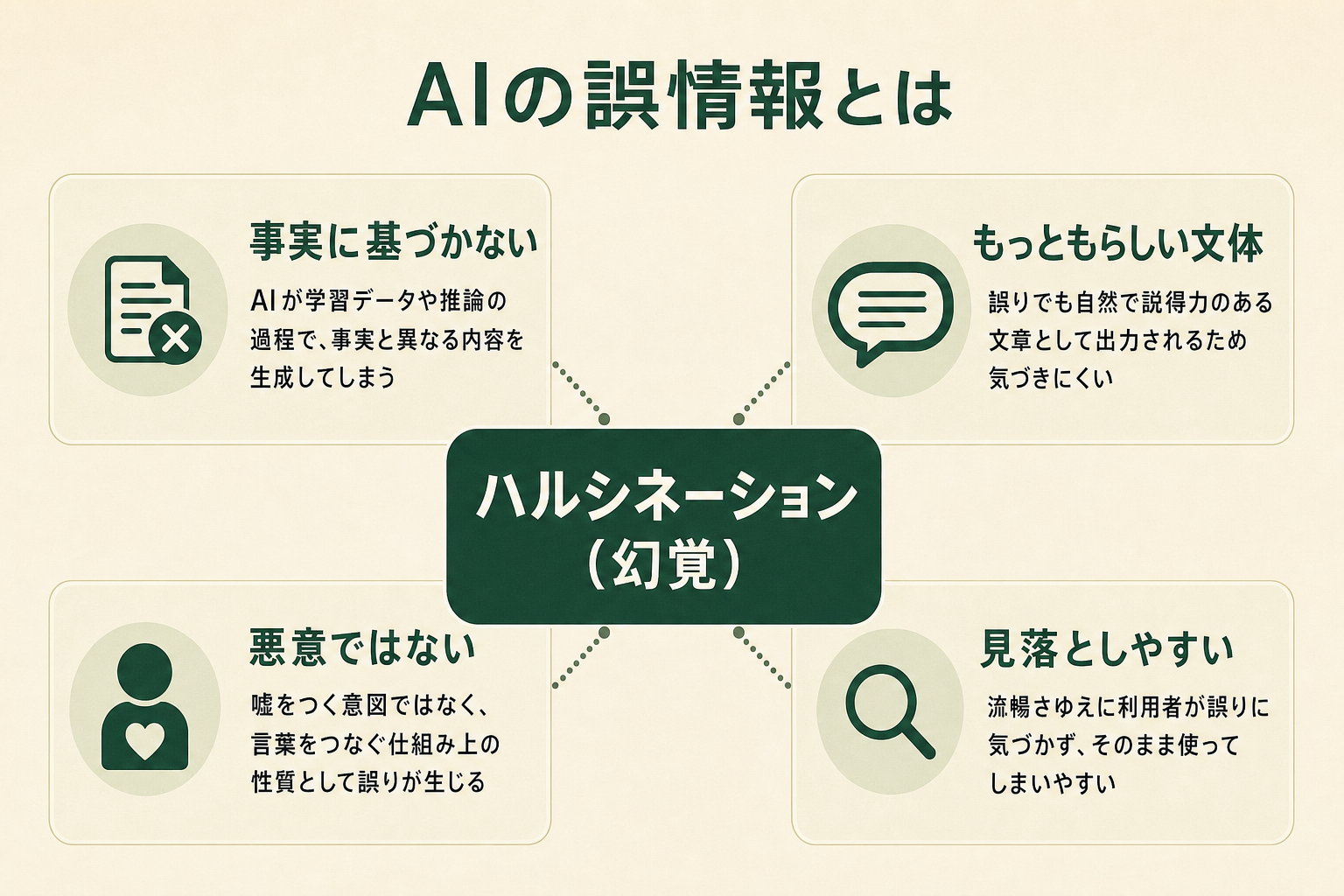
ハルシネーションとは、生成AIが事実に基づかない、もっともらしい誤った情報を生成してしまう現象です。英語の「hallucination(幻覚)」が語源で、AIがあたかも実在するかのように見える情報を作り出す様子を、人が見る幻覚にたとえた言葉です。
特徴は、誤りであっても文章が自然で説得力を持つ点にあります。「知りません」と答えるのではなく、存在しない論文や統計、人物の経歴などを、本当らしい文体で堂々と提示してしまうため、利用者が誤りに気づきにくいのが厄介なところです。生成AIの利便性が高まるほど、このハルシネーションをどう扱うかが、活用の前提として欠かせない知識になっています。
ハルシネーションの意味|AIが見る「幻覚」
ハルシネーションは、日本語では「幻覚」と訳されることが多い言葉です。生成AIの文脈では、入力された質問に対してAIが事実と異なる回答を生成する現象全般を指します。具体的には、実在しない書籍を「参考文献」として挙げる、起きていない出来事を事実のように説明する、数字や日付を取り違える、といった形で現れます。
押さえておきたいのは、AIが意図的に嘘をついているわけではないという点です。後述するようにAIは「次に来る確率の高い単語」をつなげて文章を作る仕組みのため、結果として事実と異なる文章が「もっともらしく」生成されてしまいます。悪意ではなく仕組み上の性質として発生する点が、ハルシネーションを理解する第一歩です。
ハルシネーションが注目される背景
ハルシネーションという言葉が広く知られるようになったのは、ChatGPTをはじめとする生成AIが急速に普及し、文章作成や調べもの、業務の効率化に使われるようになったことが背景にあります。誰でも手軽に高品質な文章を得られる一方で、その回答に誤りが混ざっていれば、そのまま信じて使ってしまうリスクが生じます。
特に、AIを業務に取り入れる動きが広がるなかで、誤情報が顧客対応や社内資料に紛れ込む懸念が現実味を帯びてきました。Gartnerも、AIの信頼性と実用性を考えるうえでハルシネーションの根本原因の理解が欠かせないと指摘しています(出典: gartner.com)。生成AIを安心して使うために、まず「なぜ誤るのか」を知っておく必要があるのです。
ハルシネーションの2つの種類|内在的ハルシネーションと外在的ハルシネーション
ハルシネーションは、誤りの発生パターンによって「内在的ハルシネーション」と「外在的ハルシネーション」の2種類に大きく分けられます。どちらの誤りなのかを意識すると、原因の切り分けや対策の選び方がしやすくなります。下表は、2つの種類の違いを発生のしかた・具体例・対処の方向性で整理したものです。実務では、両方が混在し得る前提で出力を確認する視点が欠かせません。
| 観点 | 内在的ハルシネーション | 外在的ハルシネーション |
|---|---|---|
| 発生のしかた | 与えた情報・学習データの内容と矛盾する誤り | 学習データにない情報を、事実のように補って生成する誤り |
| 具体例 | 入力文には「2023年」とあるのにAIが「2021年」と回答する | 存在しない論文名や統計を、もっともらしく作り出す |
| 対処の方向性 | 入力情報との照合・要約タスクでの検証 | 出典の確認・外部情報源との突き合わせ |
たとえば社内文書を要約させたときに原文と食い違う内容が出れば内在的、一般的な質問に対して根拠のない事実を付け足してくれば外在的、というように切り分けられます。
内在的ハルシネーション(与えた情報と矛盾する誤り)
内在的ハルシネーションは、AIに与えた入力情報や、学習したデータの内容と矛盾する誤りを指します。たとえば、要約を依頼した文章の中に書かれている事実を、AIが取り違えて別の内容として出力するケースです。元の情報自体は正しくても、それを処理する過程で歪んでしまうのが特徴といえます。
このタイプは、入力した情報と出力を突き合わせれば比較的気づきやすい誤りです。要約・翻訳・分類といった「与えた情報をもとに処理するタスク」で発生しやすいため、元の文章とAIの回答を照らし合わせる確認を習慣にすることで、多くを防げます。
外在的ハルシネーション(事実確認できない情報の生成)
外在的ハルシネーションは、学習データに存在しない情報を、AIがあたかも事実のように補って生成してしまう誤りです。「この分野の代表的な論文を教えて」と尋ねたときに、実在しない論文名や著者を作り出すのが典型例です。AIは空白を埋めるように文章を続けるため、知識がない領域ほど発生しやすくなります。
このタイプは、出力された情報が本当に存在するかを外部で確認しないと気づけません。社外に出す資料や顧客への回答に使う場合は特に注意が必要で、固有名詞・数値・出典は必ず一次情報にあたって裏取りする運用が欠かせません。
ハルシネーションが起こる仕組みと主な4つの原因
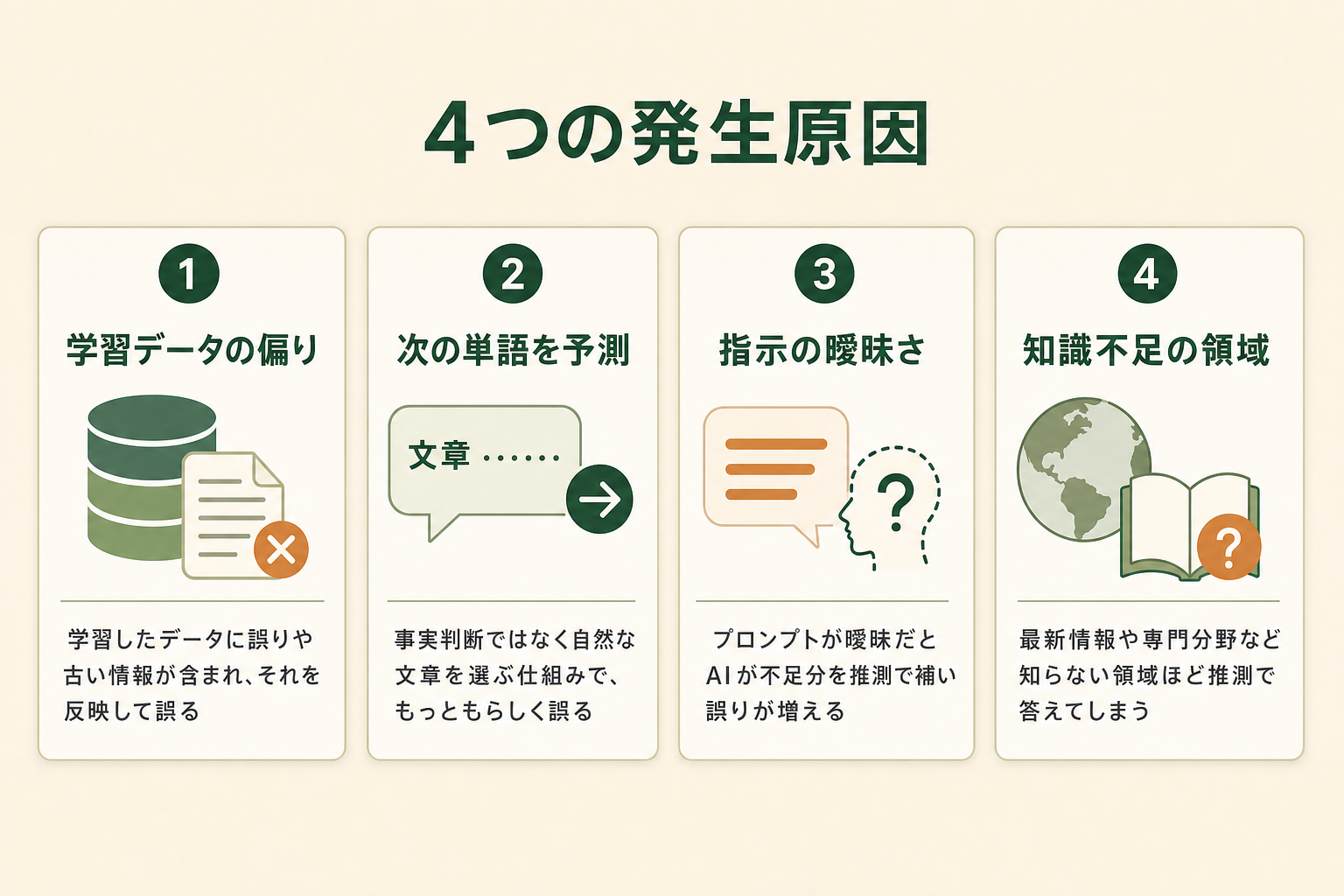
ハルシネーションが起こる根本には、生成AI(大規模言語モデル、LLM)が「次に来る確率の高い単語を予測してつなげる」という仕組みで動いている点があります。AIは事実を理解して答えているのではなく、自然な文章になるよう言葉を選んでいるため、結果として誤りがもっともらしく生成されます。ここでは、その仕組みを踏まえた主な原因を4つに整理します。
関連記事:ChatGPTの仕組みとは?生成AIの基本から学習方法までわかりやすく解説
原因1|学習データの偏り・誤り・古さ
生成AIは大量のテキストデータを学習していますが、そのデータに偏りや誤り、古い情報が含まれていれば、それを反映した回答を生成します。学習データに正確な情報が不足している領域では、AIは不確かな知識をもとに回答を組み立てるため、誤りが生じやすくなります。
また、AIの学習には区切りとなる時点があり、それ以降の最新情報は反映されていません。新しい製品やサービス、直近の出来事について尋ねると、古い情報や推測で答えてしまうのは、この学習データの鮮度が原因です。
原因2|「次の単語を予測する」というLLMの仕組み
LLMは、入力された文章に続く「最も自然な単語」を確率的に選び続けることで回答を生成します。この仕組みは流暢な文章を作るのに優れている一方で、「事実かどうか」を判断する機能を本質的には持っていません。文章としてのもっともらしさと、内容の正しさが必ずしも一致しないのです。
そのため、AIは「わからない」と答えるよりも、確率的にありそうな単語をつなげて回答を続けてしまう傾向があります。空白を埋めようとする性質が、結果として存在しない情報の生成につながります。これはハルシネーションが完全にはなくせない理由でもあります。
原因3|プロンプト(指示)の曖昧さ
AIへの指示であるプロンプトが曖昧だと、AIは不足した前提を自分で補おうとし、その過程で誤った情報を生成しやすくなります。「〇〇について教えて」とだけ伝えると、AIはどの範囲・どの粒度で答えるべきか推測で埋めるため、意図しない方向の回答や根拠の薄い内容が混ざります。
逆に、前提条件・対象範囲・出力形式を具体的に指示すれば、AIが推測で補う余地が減り、ハルシネーションを抑えられます。曖昧な質問ほど誤りが増えるという関係は、後述する対策にも直結します。
原因4|最新情報・専門領域の知識不足
AIが学習していない最新の話題や、ニッチな専門領域に関する質問では、ハルシネーションが特に起こりやすくなります。手元に確かな知識がない状態でも、AIは回答を生成しようとするため、推測や一般論を事実のように述べてしまうのです。
医療・法律・金融など、情報の正確性が強く求められる専門分野では、この知識不足による誤りが大きなリスクになります。専門性の高い内容をAIに尋ねる際は、回答をうのみにせず、専門家や一次情報で必ず確認する姿勢が求められます。
ハルシネーションが招くリスクと実際の事例
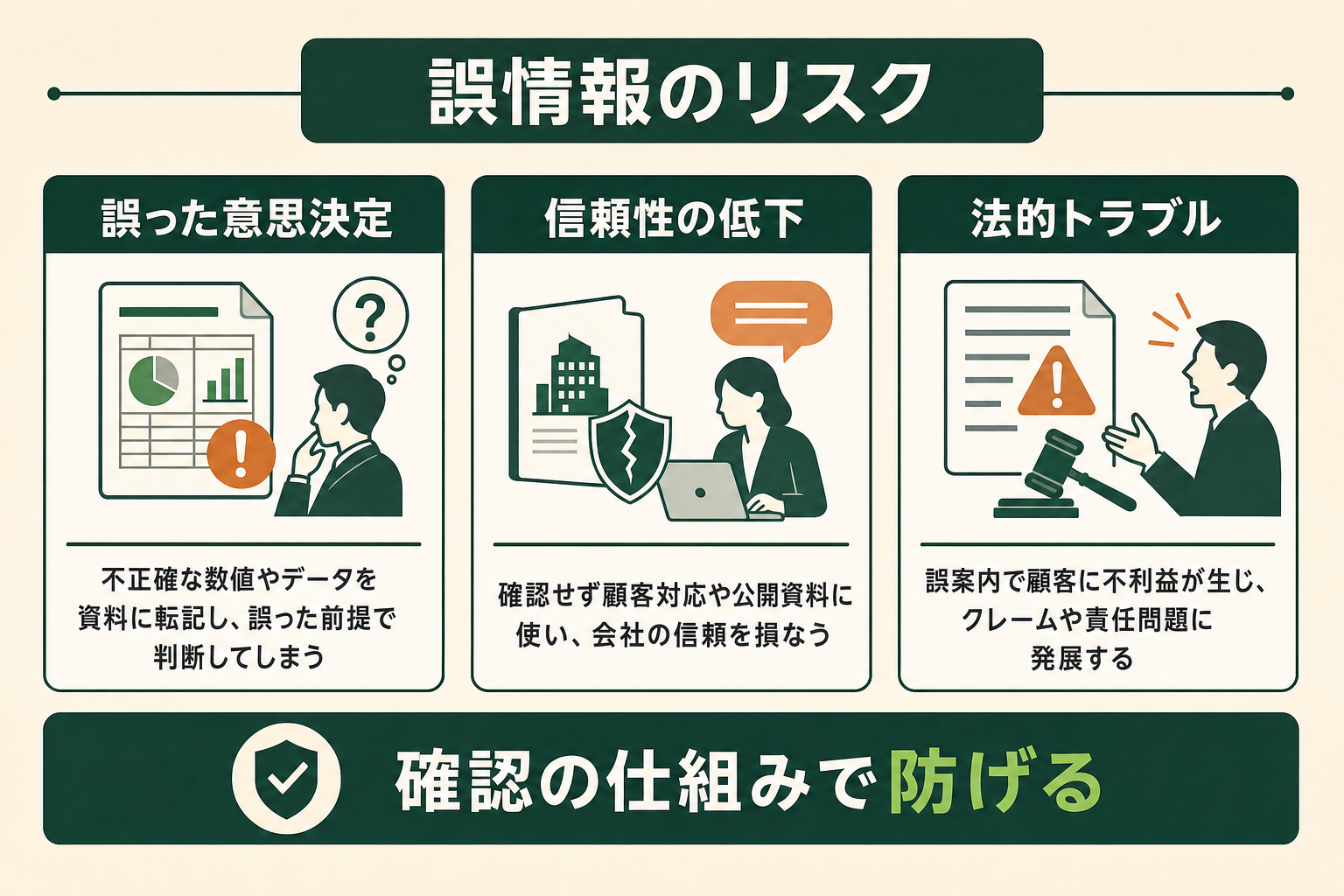
ハルシネーションの怖さは、誤りが「もっともらしい」ために見過ごされ、そのまま意思決定や情報発信に使われてしまう点にあります。個人の調べものであれば影響は限定的でも、業務で使う場合は、誤情報が組織やサービスの信頼に直結します。ここでは代表的なリスクと、実際に問題となった事例を見ていきます。
関連記事:生成AIで気をつけるセキュリティとは?主要リスクと企業がとるべき対策を解説
誤情報の拡散と意思決定の誤り
ハルシネーションによる誤った情報をそのまま信じて使えば、誤った前提で判断を下すことになります。AIが生成した不正確な市場データや数値を資料に転記すれば、その資料を見た人全員が誤情報をもとに動くことになりかねません。誤りが一次情報のように扱われ、組織内で拡散していくのが大きなリスクです。
特に、AIの回答が流暢で説得力があるほど、人は内容を疑いにくくなります。「AIが言っているから正しい」という思い込みが、本来必要なはずの確認をスキップさせてしまう点に注意が必要です。
企業の信頼性低下・法的リスク
AIが生成した誤情報を、確認しないまま顧客への回答や公開資料に使ってしまうと、企業の信頼性を損なう事態につながります。誤った案内によって顧客に不利益が生じれば、クレームやトラブルに発展し、場合によっては法的な責任が問われる可能性もあります。
こうしたリスクを踏まえ、総務省・経済産業省のAI事業者ガイドラインでも、ハルシネーション等の技術的リスクや、偽・誤情報の生成・拡散がAIのリスクとして明記されています(出典: soumu.go.jp)。事業者には、リスクを理解したうえで自主的に対策に取り組むことが求められています。
実際に起きたハルシネーションの事例
ハルシネーションは、すでに具体的なトラブルとして表面化しています。代表的なのが、AIが実在しない判例や論文を「存在する」かのように生成してしまうケースです。海外では、弁護士がAIの回答をもとに作成した書面に、実在しない判例が複数引用されていたことが問題となった例が報じられています。
このほかにも、企業の問い合わせ対応AIが事実と異なる案内をしてしまった事例など、業務での利用が広がるほどハルシネーションの影響範囲も広がっています。便利だからこそ、誤りが混ざる前提で使い方を設計することが欠かせません。
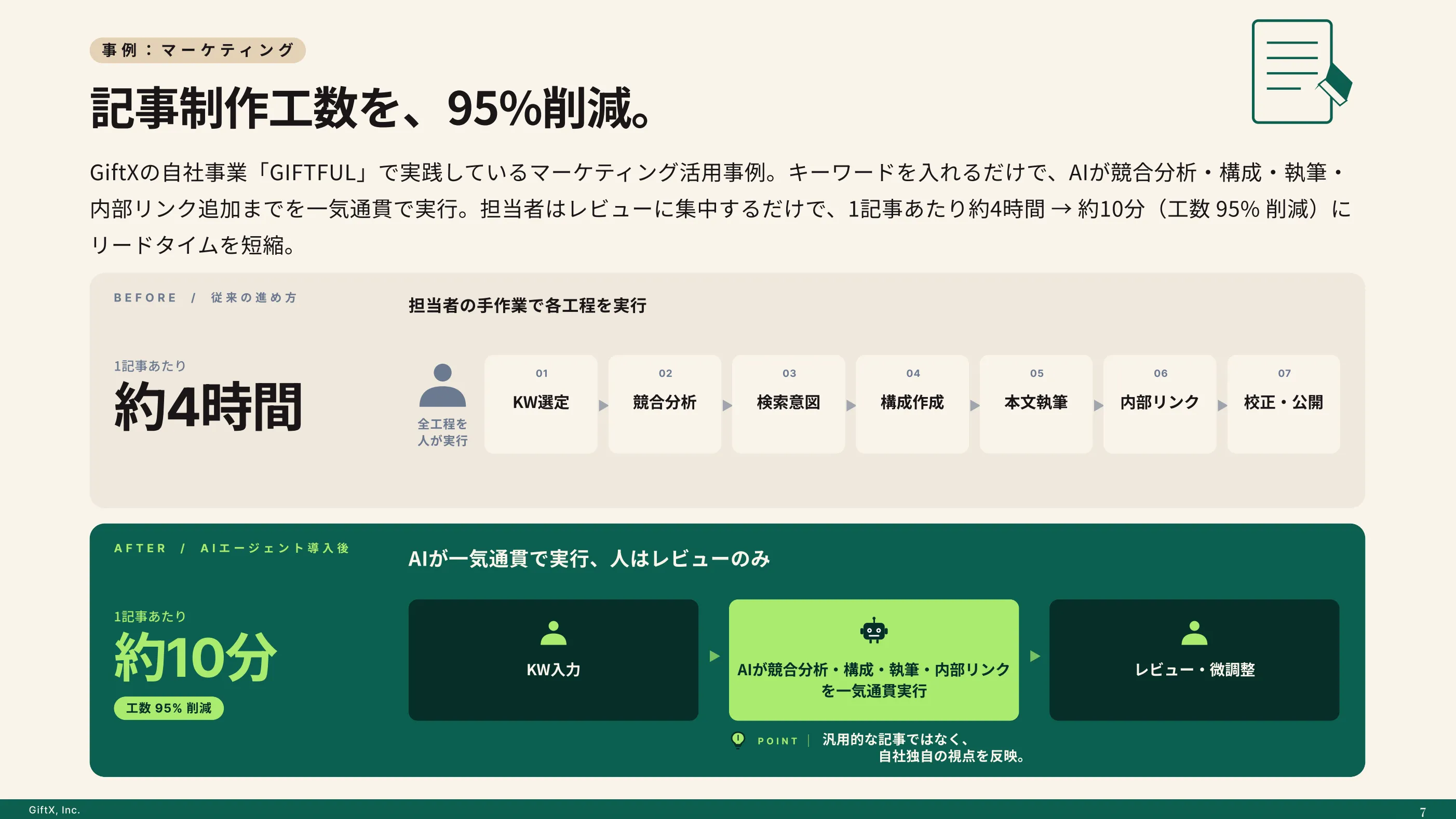
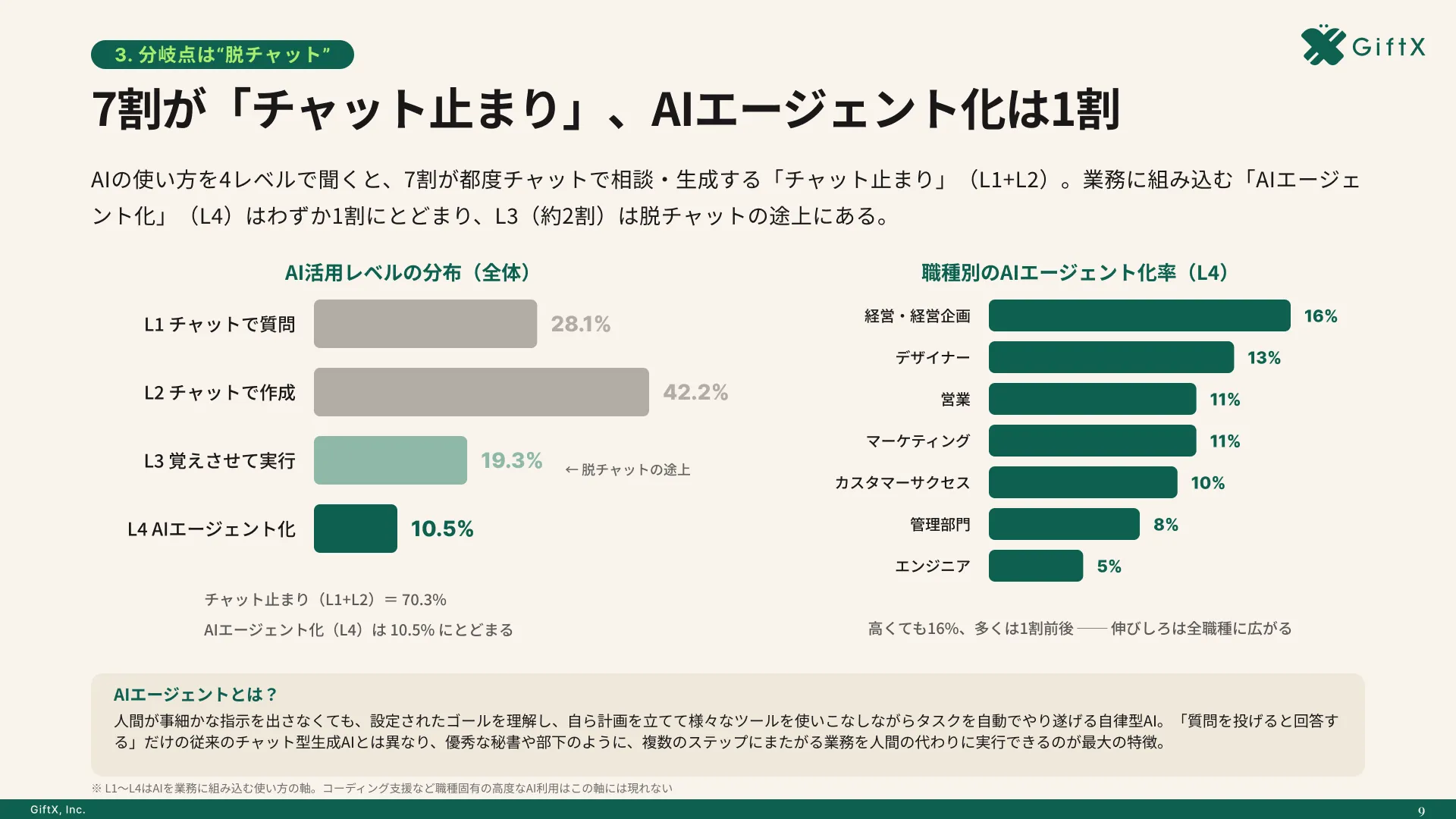
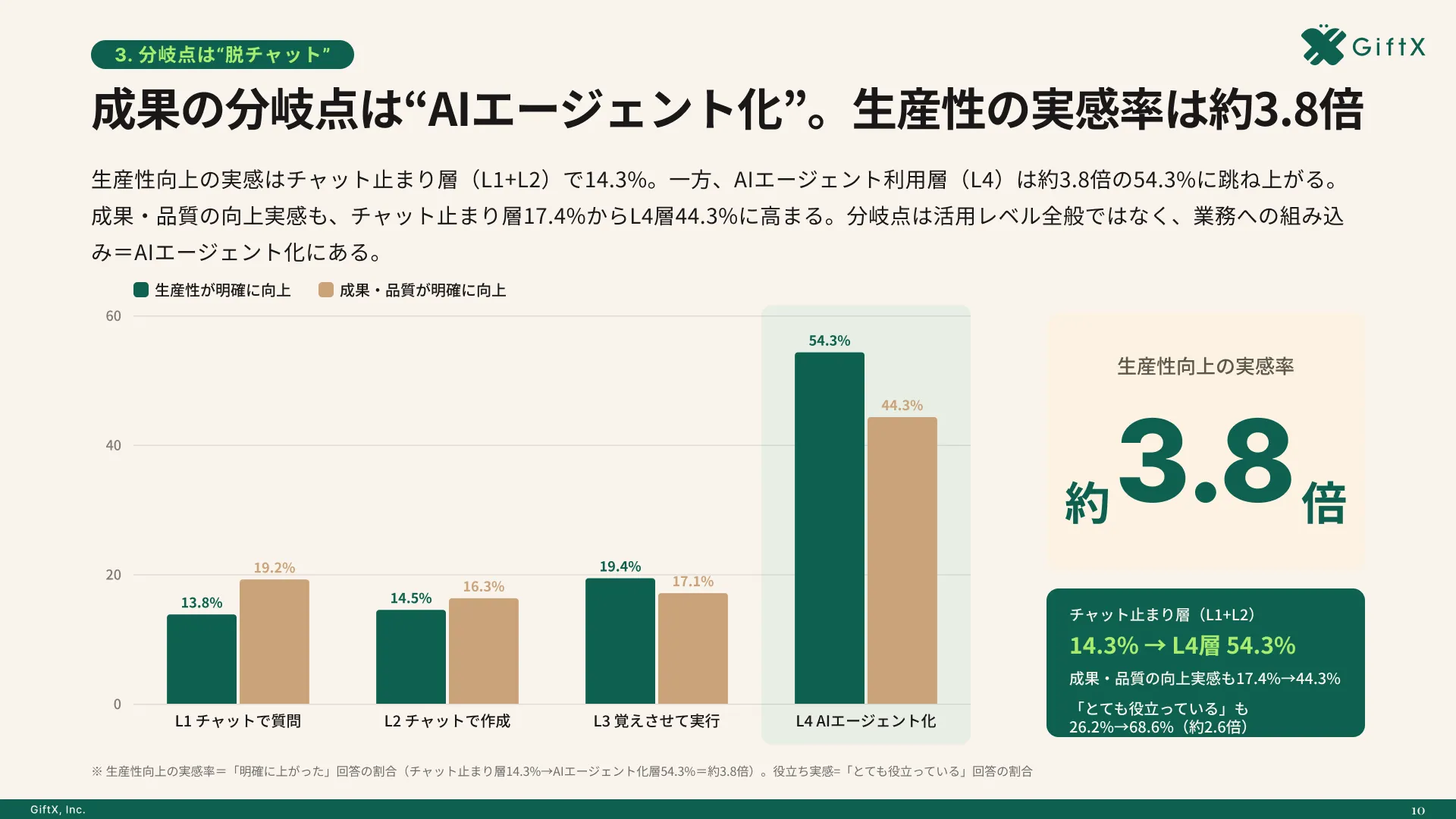
全国8,000人調査で、AI活用方法によって生産性向上に約3.8倍の差が生まれることが判明。
ハルシネーションを防ぐ5つの対策
ハルシネーションは仕組み上、完全にゼロにはできませんが、使い方を工夫すれば発生を大きく減らし、影響を最小化できます。鍵となるのは「AIに正しく答えやすい状況を作る」ことと「人による確認を仕組みに組み込む」ことの両面です。ここでは、すぐに実践できる5つの対策を紹介します。
対策1|プロンプトで前提と出典を明確に指示する
ハルシネーションを抑える最も手軽な方法は、プロンプトを具体的にすることです。前提条件・対象範囲・出力形式を明確に伝えれば、AIが推測で補う余地が減ります。「わからない場合は推測せず『わからない』と答えてください」「出典が確認できる情報だけを挙げてください」と一文添えるだけでも、根拠の薄い回答を減らせます。
また、参考にしてほしい資料や前提情報をプロンプトに含めて渡すと、AIはその範囲内で回答しやすくなります。曖昧な質問を投げっぱなしにせず、AIが答えやすい土台を整えることが、最初の対策になります。
対策2|RAG(検索拡張生成)で根拠情報を与える
RAG(検索拡張生成)は、AIが回答を生成する前に、信頼できる社内文書やデータベースを検索し、その内容を根拠として回答させる仕組みです。AIが自分の記憶だけで答えるのではなく、確かな情報源を参照して回答するため、外在的ハルシネーションを大きく減らせます。
社内マニュアルや製品情報など、正確性が求められる領域でAIを活用する場合、RAGは特に効果的です。最新情報や自社固有の情報を扱う業務では、AI単体ではなく、根拠データと組み合わせて使う設計が信頼性の鍵になります。
対策3|ファクトチェックを業務フローに組み込む
どれだけ工夫しても、AIの出力をそのまま信じてよい状態にはなりません。AIが生成した固有名詞・数値・日付・出典は、人が一次情報にあたって確認する手順を、業務フローにあらかじめ組み込んでおくことが欠かせません。「AIが作った後に必ず人が確認する」という流れを標準化すれば、誤りが外に出る前に止められます。
特に、社外に公開する資料や顧客への回答に使う場合は、確認を省略しないルールづくりが欠かせません。AIは下書きを高速に作る担当、人は事実を保証する担当、という役割分担を明確にすると運用が安定します。
対策4|複数のAIや情報源で出力を照合する
1つのAIの回答だけに頼らず、複数のAIに同じ質問を投げて回答を比べる、あるいは検索エンジンや公式情報と突き合わせるのも有効な対策です。回答が食い違う部分は、ハルシネーションが疑われる箇所として重点的に確認できます。
重い判断に関わる情報ほど、ひとつの回答をうのみにせず、別の手段で裏取りする姿勢が求められます。手間はかかりますが、誤情報による損失と比べれば、照合のコストは十分に見合うものといえます。
対策5|社内ガイドライン整備とAIリテラシー教育
個人の工夫だけに頼らず、組織として「AIをどう使うか」のガイドラインを整備することも欠かせません。どの業務でAIを使ってよいか、出力をどう確認するか、誰が責任を持つかをルール化しておくことで、ハルシネーションによるトラブルを未然に防げます。
あわせて、使う人がハルシネーションの存在を理解しているかどうかが効いてきます。「AIの回答には誤りが混ざり得る」という前提を全員が共有していれば、確認を怠るリスクが減ります。ツールの導入と並行して、リテラシー教育を進めることが安全な活用につながります。
生成AIを業務で活用するときに陥りがちな3つの落とし穴
ハルシネーション対策を理解したうえで生成AIを業務に取り入れようとすると、多くの現場が同じところでつまずきます。ここでは、活用を始めるときに陥りがちな3つの落とし穴と、それを避けるための結論を紹介します。
落とし穴1:いきなり全てをやろうとする
最初から複数の業務を一度にAI化しようとすると、確認体制が追いつかず、ハルシネーションの見落としが起きやすくなります。対象を広げるほど検証の負荷も増えるため、最初は1つの業務に絞るのが進めやすい方法です。
落とし穴2:壮大なAI戦略から考えて手が止まる
全社的なAI活用構想から考え始めると、検討に時間がかかり、なかなか実行に移せません。大きな絵を描くこと自体は悪くありませんが、先に小さく試して手応えを得るほうが、学びも早く得られます。
落とし穴3:既製品のチャット型AIでは業務フローに組み込めない
汎用的なチャット型AIをそのまま使うだけでは、自社の業務に合わせた前提情報や確認手順を組み込みにくく、ハルシネーション対策を含めて精度を業務水準まで高めるのが難しくなります。業務フローに沿った形に作り込めるかどうかが、安定運用の分かれ目です。
スモールスタートで1業務をAIエージェントに任せる
これらの落とし穴を避けるポイントは、スモールスタートで1業務をAIエージェントに任せることです。対象を1つに絞れば、ハルシネーションの確認も無理のない範囲に収まり、効果を見極めながら安全に広げていけます。まず小さく始め、根拠データの参照や確認手順まで含めて業務に組み込むことが、生成AIを実務で活かす近道です。GiftXでは、こうしたスモールスタート前提のAIエージェント構築を1業務単位から伴走支援しています。詳細はAIエージェント構築支援サービスをご覧ください。
ハルシネーションに関するよくある質問
最後に、ハルシネーションについて検索者からよく寄せられる質問に簡潔に回答します。
ハルシネーションを日本語で言うと?
ハルシネーションは、日本語では「幻覚」と訳されます。生成AIの文脈では、AIが事実に基づかないもっともらしい情報を生成してしまう現象を指す言葉として使われています。
ハルシネーションは完全になくせる?
現時点では、ハルシネーションを完全にゼロにすることはできません。生成AIが「次に来る確率の高い単語」を予測して文章を作る仕組み上、誤りが生じる可能性は残ります。そのため、発生を減らす工夫と、人による確認を組み合わせて影響を抑えることが現実的な向き合い方です。
ハルシネーションが起こりやすいのはどんなとき?
学習データに含まれない最新の話題、ニッチな専門領域、曖昧な指示で質問したときに起こりやすくなります。逆に、前提や出典を明確に指示し、根拠データを与えると発生を抑えられます。
まとめ|ハルシネーションを正しく理解し、対策しながら生成AIを活用する
ハルシネーションとは、生成AIが事実と異なるもっともらしい情報を生成してしまう現象です。学習データの偏りや、確率的に単語をつなぐLLMの仕組み、プロンプトの曖昧さ、専門知識の不足などが主な原因で、誤情報の拡散や信頼性の低下といったリスクにつながります。プロンプトの工夫、RAGの活用、ファクトチェックの組み込み、複数情報源での照合、ガイドライン整備といった対策を重ねれば、生成AIは安全に活用できます。
大切なのは、ハルシネーションをゼロにしようとするのではなく、誤りが混ざる前提で使い方を設計することです。まずは1つの業務から小さく始め、確認手順まで含めて生成AIを取り入れていくことが、リスクを抑えながら成果を出す近道になります。
AIエージェントの活用をご検討の方へ
本記事で紹介したように、生成AIをハルシネーションのリスクを抑えながら業務で活かすには、確認手順や根拠データの参照までを含めて、自社の業務フローに合わせた設計が欠かせません。自社の業務で具体的に進めたい・相談したいとお考えの方は、ぜひGiftX AIエージェント構築支援までお問い合わせください。
GiftX AIエージェント構築支援では、貴社の業務に合わせて1業務単位のスモールスタートから本番運用まで、AIエージェント構築をワンストップで支援します。ユースケースの洗い出しから、PoC、本番運用、社内ナレッジ化まで伴走します。
AI活用にご関心のある方は、ぜひ一度ご相談ください。
▶ GiftX AIエージェント構築支援の詳細・お問い合わせはこちら