
作ったもの:本人が喋る、縦型のショート動画
できあがったのは、本人がカメラに向かって話す数秒の縦型動画です。声は合成のナレーションではなく、本人の声をクローンしたもの。喋りながら、手ぶりや表情も自然に動きます。
今回の題材は、ちょっとした”つかみ”として、本人がワールドカップの試合予想を語る、という内容にしました。中身は何でも差し替えられます。台本のテキストを変えるだけで、同じ見た目・同じ声のまま、別の話をさせられる——そういう仕組みになっています。
どう作ったか:全体像
流れは、ざっくり3ステップです。
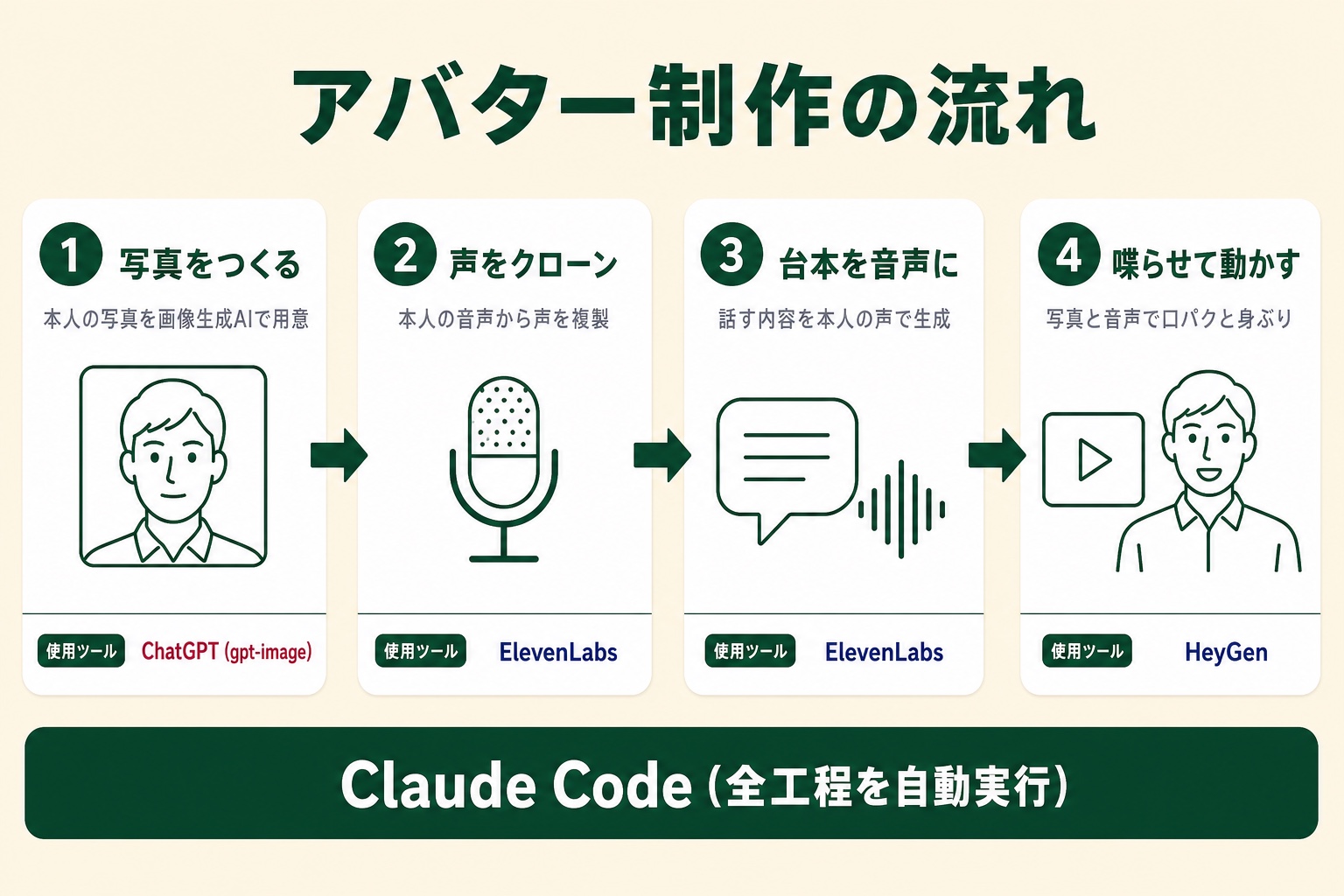
- 写真をAIで整える — 背景の差し替えやロゴ入れを、言葉で指示して加工する
- 声を”本人”にする — 本人の音声から、声をクローン(複製)する
- 喋らせて、動かす — 写真と声を渡して、口パク+身ぶりの動画にする
材料は「写真一枚」「数分の音声」「台本テキスト」だけ。この3ステップを順に通すと、本人が喋る動画になります。各ステップの実作業はClaude Codeが自動で進めてくれるので、人間がやったのは、要所で「これでいこう」「もう少しこう」と決めることくらいです。
各ステップの詳細
ステップ1|写真をAIで作る
最初に用意するのは、アバターの”素体”になる人物写真です。今回は既存の写真を加工するのではなく、Claude Code から画像生成AIに指示して、書斎にいる本人のカットを一枚つくりました。
使ったのは ChatGPT の画像生成(gpt-image)。背景も服装も、胸元のロゴまで、ぜんぶ言葉で「こうしてほしい」と頼むだけで仕上がります。編集ソフトは開かず、文章で指示するだけで、このあとのアバターの”素体”が完成します。

ステップ2|声を”本人”にする(一番の山場)
ここが、今回いちばん粘ったところです。
やりたいのは「本人の声で喋らせる」こと。合成音声はたくさんありますが、“他人の声”では意味がありません。そこで、本人の音声を数分ぶん用意して、ElevenLabs で声をクローンしました。
ところが、一発ではうまくいきません。最初の声は「本人っぽいけど、どこか違う」。落ち着きが足りなかったり、語尾が不自然に上がってしまったり。そこから、ツールを変え、声の”落ち着き”や”話す速さ”、語尾の上がり下がりを少しずつ調整していきました。
面白かったのは、効きどころが設定値だけではなかったこと。台本の句読点ひとつで、読み上げの間や抑揚が変わります。「!」を「。」に変えるだけで、言い切りになって落ち着く。最終的に「これは本人だ」と思える声にたどり着いたときは、ちょっと感動しました。
ステップ3|喋らせて、動かす
声ができたら、いよいよ写真を喋らせます。ここで使ったのは HeyGen(写真から喋る動画をつくるツール)です。写真と声を渡すと、口元が音に合わせて動く”喋る写真”ができあがります。
ただ、最初の版は「顔だけが動いて、体は固まったまま」。これがどうしてもAIっぽく、不自然でした。そこで、表情や身ぶり手ぶりまで付く方式(HeyGen の Avatar IV)に切り替えます。動きが付くだけで、ぐっと”人”に近づきました。
制作の裏側:うまくいった工夫
ここからは、同じものを作ってみたい方向けに、少し実践寄りの話を。今回の勘どころは、大きく三つでした。
ツールは、役割分担させる
AIツールを一つに絞らず、得意分野で使い分けたのが正解でした。「喋る人物」は HeyGen、「写真の加工や映像の演出」は Higgsfield、「声」は ElevenLabs、という具合に使い分けました。
一台でぜんぶやろうとすると、どこかが弱くなる。実際、最初は映像が得意なツール(Higgsfield)に喋らせようとして、日本語のセリフが崩れてしまい、やり直しました。テキストから読み上げる方式に変えたら、日本語はぴたりと安定します。AIでも”適材適所”でした。
声の精度は、“元の録音”でほぼ決まる
声づくりで一番効いたのは、設定をいじることではなく、良い録音を用意することでした。静かな場所で、きれいに、長めに録るほど、似ます。逆に言うと、素材が粗いと、どれだけ設定を詰めても頭打ちになる。次に作るときは、まず録音から、と心に決めました。
動きの指示は「一行一動作」で短く
身ぶりを増やそうと「もっといろいろ動いて」と長い文章で頼んでも、まったく変わりませんでした。調べてみると、動きの指示は”一行に一動作”で短く書くのがコツ。「両手を顔の高さまで上げる」「ガッツポーズをする」——こう分けて書いたら、ちゃんと反映されました。
そして正直に言うと、きれいに一発でできたわけではありません。声も、動きも、写真も、「これは違う」を何度も重ねた末に「これだ」へたどり着いています。
それでも苦にはなりませんでした。試行錯誤がぜんぶテキストのやり取りで完結するので、回すのが速い。気軽に何度でも試せるのが、いまのAIのいちばん面白いところかもしれません。
作って終わりにしない:アバター動画生成エージェントにした
今回のもうひとつのポイントは、作って終わりにしなかったことです。完成後、このワークフロー全体を、Claude Codeのエージェント(スキル)にまとめました。
写真と声をいちど用意しておけば、あとは台本のテキストを渡すだけ。同じ見た目・同じ声のアバターが別の話をする動画を、ほぼ自動で量産できる状態になっています。一回かぎりの”作ってみた”が、繰り返し使える仕組みに変わりました。
まとめ
写真一枚から、本人が喋って動く動画ができる。少し前なら考えられなかったことが、いまは”その日のうちに”できてしまいます。
もちろん、まだ万能ではありません。大きな動きは苦手だし、細かいニュアンスには人の手が要る。それでも、「まずやってみる」のハードルが劇的に下がったのは確かです。そして、つまずきの一つひとつが、次の制作を速くする”勘どころ”になっていきます。
GiftXは、「人の温かみを宿した進化を。」をミッションに掲げています。自分たちでまず触ってみて、面白さも限界も体で分かった上で、企業のAIエージェント構築支援を行っています。自社でのAI活用に興味のある方は、お気軽にご相談ください。


